
It’s the paper dance, done automagically (one of the authors is a Dancing Machine, the other, not so much):
arXiv:1009.2203 [scirate arxiv]
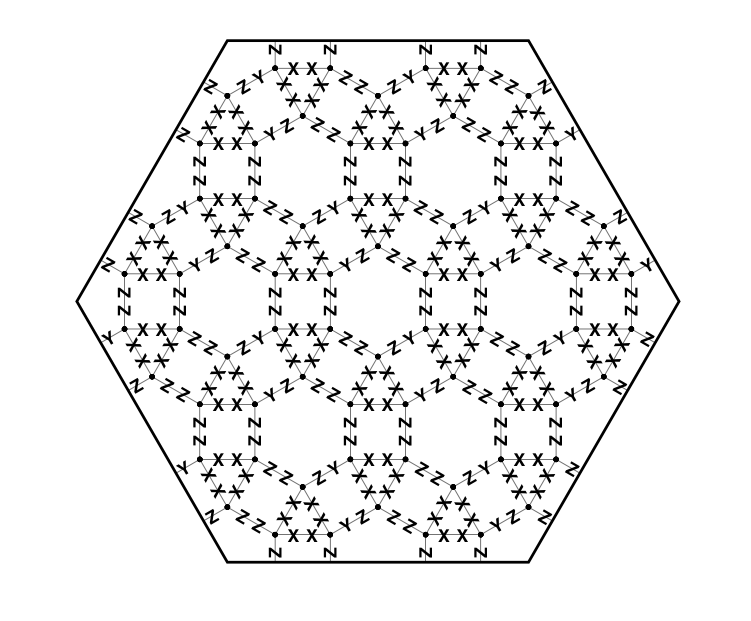
Automated searching for quantum subsystem codes by Gregory M. Crosswhite, Dave Bacon
Quantum error correction allows for faulty quantum systems to behave in an effectively error free manner. One important class of techniques for quantum error correction is the class of quantum subsystem codes, which are relevant both to active quantum error correcting schemes as well as to the design of self-correcting quantum memories. Previous approaches for investigating these codes have focused on applying theoretical analysis to look for interesting codes and to investigate their properties. In this paper we present an alternative approach that uses computational analysis to accomplish the same goals. Specifically, we present an algorithm that computes the optimal quantum subsystem code that can be implemented given an arbitrary set of measurement operators that are tensor products of Pauli operators. We then demonstrate the utility of this algorithm by performing a systematic investigation of the quantum subsystem codes that exist in the setting where the interactions are limited to 2-body interactions between neighbors on lattices derived from the convex uniform tilings of the plane.
With pictures:
and with code to boot: http://github.com/gcross/CodeQuest/downloads.
{kind=link}
would some sort of aperiodic construction work? [head explodes]
I love those pictures! (and the paper makes a lot of sense…)
Very interesting! Of course everyone is going to ask when you’re going to do the snub hextille (the lattice, not the dance).
Do you conjecture that any of the patterns you found will, when scaled, grow both in the number of protected qubits and in their distance? This seems like the natural goal. I think the pattern in Figure 14b in particular deserves a proper name and a complete analysis; it is simple enough that one would expect someone eventually to find it “by hand” if they were clever enough. Is there some relationship between a code that does scale in both ways and a lattice supporting (discretized) anyons?
In some sense a competitive advantage of the more complicated lattices, in the approach of this paper, is simply that the repeating unit cell is large enough to allow a large search space. An obvious direction for future work is to keep the underlying lattice simple–quadrille or deltille–but with a larger fundamental domain. If you also allow a “knocked out” labeling on edges, it seems reasonable to suppose that every interesting lattice code could be found with such an embedding, just as every planar graph has a homotopic embedding in the infinite grid.
arXiv version, p. 25: “Figure figure:boundaries”
p. 30: “smaller than that the for most”
@ Tracy: “Do you conjecture that any of the patterns you found will, when scaled, grow both in the number of protected qubits and in their distance?”
According to the results in
http://arxiv.org/abs/1008.1029
the upper bounds kd=O(n) and d^2=O(n) apply to our situation, where k is the number of logical qubits, d is the distance, and n is the number of physical qubits. Since all of the codes we found with extrapolatable trends had k = O(n), this implies that d = O(1) and so we would not expect the distance to grow with the number of qubits. It is harder to make a judgment call for the rhombihexadeltille tiling, though, because there is not enough information to extrapolate with confidence. It is conceivable, though, that one could see a trend where k = O(sqrt(n)) and d = O(sqrt(n)).
Also, thank you for pointing out our typos. 🙂
Hi Dave,
Can you post a non-specialist summary on this paper some time? The paper seems interesting, but I can’t really tell how it fits into the big picture of the current QEC / fault tolerance literature.
Thanks,
Joe
Gregory and Dave, please let me say that I thought that article was outstanding … interesting … well-written … and visually beautiful too.
May I suggest that you include a reference to Branko Grünbaum’s book Tilings and Patterns … if you walk up the street to the UW Math Library, and look on the shelves, you’ll find out why! And maybe send Branko a copy of your manuscript? He would be very pleased to see it, I am 100% sure!
Your article uses the word in theorem in 32 places, lemma in 100 places, and code in 206 places, and it struck me that there must necessarily be a pretty tight parallelism between the theorems and the code. So would the following be feasible, do you think? Write out a one-page theorem summary, and a one-page code summary, such that the two summaries have a section-by-section parallel structure.
I suggest this exercise because it is precisely what we are attempting to do across the street, and so we know (from personal experience) that it is a fun exercise. In our case, we start with a summary of theorems in-hand, and we write pseudo-code to match it. In your case, you have the pseudocode already in-hand … so could a theorem summary be written that directly paralleled it?
This approach arose from our colleague Jon Jacky’s recent assertion (at one of our group meetings) that “Theorems are to algorithms as compilers are to code.” Whether Jon is right is not entirely clear (to me), but I *have* been impressed that a well-organized set of theorems maps very naturally onto well-organized (symbol-manipulating) pseudocode … to such an extent that nowadays pretty much all of our simulation algorithms/codes are being developed in this rather rigidly formalized and semi-automated way.
The practical result is that we never work directly with indices any more … or even with directly with variable names … any more than we look at the assembly code produced by compilers … `cuz gee … indices? … coordinates? … that’s work for robots. The role of humans then moves to the next-higher level of abstraction, which in practice consists largely of drawing commutative and projective diagrams.
As Monte Python says in their skit Four Yorkshiremen: “Luxury!” And in practice, there’s pretty much no alternative way to develop large-scale codes—for classical, quantum, *or* hybrid engineering—with any realistic expectation of implementing validation and verification procedures in a systematic way.
Needless to say, associated to this still-evolving engineering schema is a higher level of typography … which you have surely achieved in your beautiful-looking manuscript. Are you using TikZ & PGF? If so, that’s impressive. Or are you using some alternative typographic package? If so … well, heck … that’s even more impressive! 🙂
As a followup to the above, here’s a link to our theorem summary, which we drafted in such a way that the associated code instantiation is not “pseudo”, but rather, is evaluatable Mathematica code that in turn writes executable LAPACK/MATLAB code. Perhaps we might get together sometime and exchange instantiation idioms? … and yes, we do use TikZ & PGF to illustrate the diagram-chasing; if there’s a better package we’d definitely like to know about it.
Now that our QSE Group’s eyes are open to it, it appears (to us) that diagram-chasing methods are propagating throughout the engineering literature …. there is IMHO pretty much zero chance that this trend will reverse anytime soon … and the beautiful graphical representations of your own article illustrate why these proof methods are gaining momentum so rapidly in practical engineering.
As a concrete example, I refer you to arXiv:math/0508365v2, “Lie group variational integrators for the full body problem”, Figure 7, captioned “Commutative cube of the equations of motion” … with the remark that any engineering graduate student could contemplate first author (and then-student) Taeyoung Lee’s subsequent career arc with reasonable satisfaction.
Those rhombihexadeltilles you draw are downright beautiful!
Greg, thank you for that very interesting pointer to the Curry-Howard isomorphism … which I had never heard of (Jon Jacky was familiar with it, though), and in particular I did not know that the computer language Haskell was named after Haskell Curry.
Our approach to “isomorphism” is slightly different … whereas Curry-Howard is (AFAICT) an isomorphism between proofs and programs, that is “a proof is a program; the formula it proves is a type for the program”, what we are interested to establish is an isomorphism between the abstract elements of a proof, and the concrete instantiations of those elements in a program … perhaps this might be stated “a proof is an object, the instantiation of that object is the program.”
Gosh, now I worried that we should be programming in C#, objective C, C++, or even JAVA (all object-oriented languages), but in the event, we program in Mathematica (for symbol manipulation) and MATLAB (for number-crunching).
This is because the real isomorphism we want to establish is between two classic textbooks of the early 21st century: Jack Lee’s Introduction to Smooth Manifolds and Nielsen and Chuang’s Quantum Computation and Quantum Information. The one-page summary provides the theorems that establish the isomorphism between these two texts (given that the potentials that govern Lindblad’s generalized dynamics are stochastic, and also, blend symplectic with metric flow). And this approach turns out to be a relatively minor generalization of a formalism whose details Dirac worked out in the mid-1960s, which is well-known to today’s dynamicists and geometers as (what else) “the theory of Dirac constraints.” Our goal is wholly practical … large-scale quantum simulations to help us “foresee the character, caliber and duration” of the development of quantum spin microscopes.
Now, the preceding narrative has a classic academic form: We show how combining ⟨first interesting idea⟩ with ⟨second interesting idea⟩ yields ⟨desirable capabilities⟩. This approach builds upon ⟨decades-old result by famous person(s)⟩, and with straightforward improvements, holds forth reasonable hope of ⟨substantial progress toward important objective⟩.
Now, it seems to me that your and Dave’s result fits this schema rather well: “We show how applying ⟨computational search techniques⟩ to explore ⟨a large class of quantum stabilizer subsystem codes⟩ yields ⟨a practical methodology for systematic surveys of design options for quantum computers⟩. Our approach amounts to a practical instantiation of ⟨basic concepts associated to Curry-Howard isomorphism⟩that, with straightforward improvements, holds forth reasonable hope of ⟨finding better error-correction codes for quantum computation⟩.”
There is a saying among engineers that “great enterprises result from the merging two good ideas”—example: hang gliders + motorcycle engines == Wright brothers—and so I urge you to consider how this classic narrative might most aptly map onto your fine article.
Whoops, Greg … my ride home is here … gotta go! Thanks again for the pointer to the Curry-Howard literature!
Oh yeah … I forgot to mention why we use Mathematica … it’s simply because Mathematica’s kludgy mix of prefix, infix, and postfix notation, plus its kludgy system of pattern matching, is pretty well-matched to the kludgy mix of prefix, infix, and postfix notation and kludgy pattern matching of real mathematical proofs. 🙂
John, first of all I just have to tell you that Jon Jacky is right and in fact there is a whole exciting field based on this idea. In particular, what he described is known as the Curry-Howard isomorphism, which you can find more about here:
http://en.wikipedia.org/wiki/Curry%E2%80%93Howard_correspondence
In fact, there are several proof “programming languages” out there:
http://en.wikipedia.org/wiki/Proof_assistant
Personally my favorite of them is Agda, because proving feels the most like programming, and of all the proof assistants I’ve played with Agda made it easiest for me to take higher-level proving ideas and implement them as subroutines. My dream is to one day be able to code up all of my proofs in a language like this.
Conversely, the cool thing about extending the type system of language is that it lets you prove more and more properties of your code. My dream is to one day not only just write proofs using a dependently-typed language like Agda, but to also write *programs* using it so that I can write proofs using the language that my program is correct and have the compiler check them for me. There are also potential speed benefits from this approach because for example if you can formally prove that all of your array accesses will always be within bounds, then you no longer need to insert run-time checks to make sure that you didn’t screw up.
Fully dependently-typed languages are very young and in their current state they are not really ready for production use. Fortunately, many of their ideas are making their ways into mainstream languages. Part of the reason why I like to program in the language Haskell is precisely because it provides a practical programming language with a type system powerful enough that I can use it to help me guarantee that my program satisfies many invariants.
Anyway, I personally think that this budding field is very exciting so I’m glad you brought it up. 😀 It’s funny, because part of the reason why I know so much now about proof assistants is because while writing this paper I had the same thought about how it felt like I was writing code, and so I figured that there had to be tools out there that could let me write proofs in code. 🙂
Thank you very much for your feedback. I was thinking about including a citation when describing the tilings, so I will have to check out the book you suggest. I see your point regarding the one-page summaries, so I’ll think about that.
Most of the drawings were programmed by writing high-level drawing subroutines in Postscript and then writing Haskell scripts to generate files with these routines that called them with the specific data being illustrated. This setup actually worked out pretty well, though for the plots showing the codes found for each tiling I decided that high-level programming in Postscript would be too much trouble so I had my Haskell script generate calls to the low-level Postscript drawing primitives itself.
Oh, and if you want to play around with dependently typed languages and using them to prove things, you might consider downloading Coq
http://coq.inria.fr/
and Proof General
http://proofgeneral.inf.ed.ac.uk/
and then flipping your way through this tutorial
http://adam.chlipala.net/cpdt/
I personally don’t like the Coq style of specifying proofs, but the tutorial provides a good insight into how dependent types and proofs works.
Isabelle’s proofs look prettier, but to be honest I had trouble figuring out how to use the language effectively from the documentation:
http://en.wikipedia.org/wiki/Isabelle_%28theorem_prover%29
(Also it uses a different language for code and for proofs, which I didn’t like so much but which probably has advantages.)
For an example of why I like Agda, here is a little game I was able to play using it. I defined Pauli operators as follows:
data Pauli : Set where
I : Pauli
X : Pauli
Y : Pauli
Z : Pauli
Then I defined a multiplication operation (modulo phases) over them
_⋅_ : Pauli → Pauli → Pauli
X â‹… X = I
X â‹… Y = Z
X â‹… Z = Y
Y â‹… X = Z
Y â‹… Y = I
Y â‹… Z = X
Z â‹… X = Y
Z â‹… Y = X
Z â‹… Z = I
I â‹… a = a
a â‹… I = a
and then I wrote a little library that would decide proofs by trying all of the possibilities so that I could write code like
â‹…-commutative : Commutative _â‹…_
â‹…-commutative = fromYes (decideâ‚‚ (_â‹…_) (flip _â‹…_)) refl
so that the value “â‹…-commutative” now contains a proof that my multiplication operator is commutative which is guaranteed to be correct as long as you trust that the Agda type checker doesn’t have any bugs in it. This proof was computed by making a call to decideâ‚‚ which decided whether “x . y = y . x” for all x and y using brute force, followed by a call to fromYes which extracted the proof from the decision. (If decideâ‚‚ had returned no, then this fromYes wouldn’t have type-checked!)
Anyway, just had to say a little more because I want people to be aware of these things because I think they are awesome. 🙂