
Warning for typical QIP attendees —
This first talk may have some implications for the real world 🙂
Andrea Mari, Vittorio Giovannetti, Alexander S. Holevo, R. Garcia-Patron and N. J. Cerf.
Majorization and entropy at the output of bosonic Gaussian channels.
Previous Title: Quantum state majorization at the output of bosonic Gaussian channels (Plenary Talk)
abstract arXiv:1312.3545
The solution of the Gaussian optimizer conjecture by Giovannetti, Holevo, and Garcia-Patron has led to enormous progress on a web of interconnected connected conjectures about Gaussian channels. This includes the phase space majorization conjecture, the additivity and minimum output Renyi entropies conjectures, strong-converse theorems for the classical capacity of gaussian channels, the entropy-power inequality conjecture, and more! The only remaining open questions are the entropy-photon number inequality and the quantum capacity.
The proof uses a decomposition of Gaussian channels. Every phase-insensitive Gaussian channel is equivalent to a quantum-limited attenuator followed by a quantum-limited amplifier. Every phase-contravariant Gaussian channel is equivalent to a quantum-limited attenuator followed by a quantum-limited amplifier followed by a noiseless phase conjugation.
It also uses an old result about quantum beam splitters. How can the output of a beamsplitter be distinguished from two independent broadcasts of the same source? Answer: only if the broadcast was a coherent state. Therefore we have the “golden property” of a quantum beam splitter: the only input states producing pure output states for a quantum limited attenuator are coherent states.
The main result of this talk is a proof of the majorization conjecture. This addresses the question: what is the minimum noise or disorder achievable at the output state, optimizing over all possible input states? The output from a coherent input state majorizes all other output states. Namely, if 

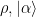
The proof uses the decomposition results mentioned above, concavity of entropy, and the breakthrough results of Giovannetti, Holevo, and Garcia-Patron. A similar result holds for any Renyi 

Here is an awesome summary of what this research project has accomplished.

Runyao Duan and Andreas Winter. No-Signalling Assisted Zero-Error Capacity of Quantum Channels and an Information Theoretic Interpretation of the Lovasz Number. Previous title: Zero-Error Classical Channel Capacity and Simulation Cost Assisted by Quantum No-Signalling Correlations
abstract arXiv:1409.3426
Coming the morning after the conference dinner, Andreas beings with a “hangover summary” of the main results:
(sometimes known to be strict)
-
-
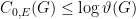
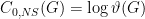
On the LHS we have the asymptotic zero-error capacity of a channel, assisted either by nothing (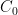
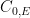
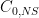
Classical zero-error capacity depends only on the transition graph, not the probabilities. A useful notion is that of confusability graph, which is an undirected graph on the input symbols of the channel where two symbols are confusable if there is a nonzero probability of confusing them. This encodes the combinatorics of the channel in a natural way. For example, product channels have a product confusability graph whose adjacency matrix is the tensor product of the confusability graphs of the factor channels. (More precisely 
The largest codebook for this channel is given by the independence number of the confusability graph; this gives the optimal zero-error capacity. It’s unfortunately NP-complete to compute this property of a graph, and even approximating it is NP hard. However, a seminal result due to Lovasz gives a convex relaxation of this into a semidefinite program, the Lovasz theta number.
Another useful bound is the so-called fractional packing number, obtained by writing down the natural integer program for independence number and replacing the 
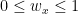
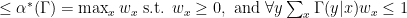
Minimizing over 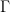


Crucially, both the Lovasz theta number and the fractional packing number are multiplicative, and therefore they bound not only the independence number, but also the capacity. Andreas said something surprising: If 
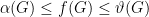
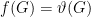
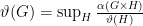
Compare with a similar formula for the fractional packing number:
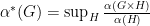
An example, in fact the usual example, is the “typewriter graph”. This has an input 
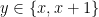

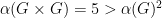
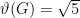
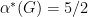
We would like to close the gap provided by the above relaxations by allowing additional resources in the encoding and decoding. Shannon did this in his 1956 paper by allowing feedback, and we can also add entanglement and no-signaling correlations.
The Lovasz theta number is in fact an upper bound to the entanglement-assisted zero-error capacity, which sometimes is larger than the unassisted zero-error capacity. This gives an operational (but partial) explanation of why the Lovasz theta function is not always a tight upper bound.
On the other hand, the fractional packing number is equal to the non-signalling-assisted capacity, which is an awesome and nontrivial result.
Now what about the quantum case? Here things get even cooler, although not everything is as well understood. For quantum channels, the quantum generalizations of the transition and confusability graphs are given by the following correspondences:

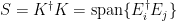
The authors have also also generalized (as in Will Matthews’ talk earlier) the notion of no-signalling operations to ones that take quantum inputs and outputs. Just as the classical no-signalling polytope is a small linear program, this quantum set has a nice SDP characterization.
Now consider 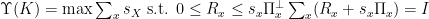

Then the “most amazing thing”, according to Andreas, is the following theorem:
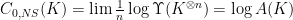
Note that this is not just an inequality, but an actual equality!
They show actually that 
The proof is reminiscent of the recent and inexplicably not-invited Fawzi-Renner breakthrough on the quantum conditional mutual information.
Now in terms of 
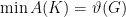
Some of the closing remarks were that

- SDP formulas for assisted capacity and simulation cost (one shot)
- SDPs can regularize to relaxed SDPs!
- Capacity interpretation of Lovasz theta number
- Is there a gap between
and
?
- Is regularization necessary?
Mario Berta, Omar Fawzi and Volkher Scholz.
Quantum-proof randomness extractors via operator space theory;
abstract arXiv:1409.3563
This talk is about producing high-quality (i.e. nearly uniform) randomness from [necessarily longer] strings that contain “lower-quality” randomness. Tools for doing this are called extractors; other closely related tools are condensers and expanders. Why would we need to do this? Well suppose we start with some uniform randomness and then leak some information about it to an adversary (Eve). Then Eve’s subjective view of our randomness is no longer uniform. Applying an extractor can make it again close to uniform. Even in a non-cryptographic setting they can be useful. Suppose we run a randomized algorithm using some large uniformly random seed. Conditioned on the output of this algorithm, the seed will no longer be uniformly random. If we want to continue using it, maybe even for later steps of a larger algorithm, we will need to clean it up using something like an extractor.
This establishes the need for extractors and their crucial property: their goal is to make a string random conditioned on some other string (e.g. Eve’s knowledge, or the earlier outputs of the randomized algorithm; call this the “side information”). This talk will consider the case when side information is in fact quantum. Conditioning on quantum things is always tricky, and one hint that the math here will be nontrivial is the fact that “operator space theory” is in the title.
One unpleasant fact about extractors is that they cannot be deterministic (this is a useful exercise for the reader). So they usually use some extra input, guaranteed to be uniform and independent of the source. The smallest possible seed size is logarithmic in the input size. Also the number of output bits can be (more or less) no larger than the min-entropy of the source. So the key parameters are the input size, the input min-entropy, the input seed size, the number of output bits and their trace distance from being uniform and independent of the side information.
One example of a nice classical result is the leftover hash lemma.
Can we still get the same result if adversary is quantum? This will have implications for privacy amplification in q crypto and also (not sure why about this one) properties of q memory.
Here min-entropy becomes the conditional min-entropy, which involves a maximization over all guessing strategies and measures knowledge of an adversary with access to a q system correlated with the source.
The main result here is a mathematical framework to study this, based on operator space theory. Why operator space? We can define C(Ext, k) to be the maximum advantage for a classical adversary against the extractor Ext on sources with k bits of min-entropy. The key insight is that this is a norm, specifically an operator norm. Sources with 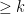
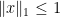
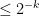


The advantage of a quantum adversary is Q(Ext, k) which is like the cb (completely bounded) version of the above. Basically suppose that instead of the entries of x being numbers they are matrices. This is kind of like what team Madrid did with nonlocal games.
They also define an SDP relaxation which has the advantage of being efficiently computable.
It follows trivially from the definitions that
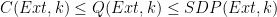
The nontrivial stuff comes from the fact that the SDP relaxations are in some cases analytically tractable, e.g. showing that small-output and high input entropy extractors are quantum-proof (i.e. secure against quantum adversaries).
A nice open question: Given that there is an SDP, can we define a convergent hierarchy?
Richard Cleve, Debbie Leung, Li Liu and Chunhao Wang.
Near-linear construction of exact unitary 2-designs
abstract
The basic idea of a unitary 
The speaker jokingly says, “unfortunately, these have a lot of applications.” This includes randomized benchmarking, decoupling and error-tolerant QKD schemes. There is another joke about how decoupling doesn’t mean breaking up (romantic) couples. But if Alice and Bob are entangled, and one passes through a decoupling map, then they end up nearly separable! That sounds like a breakup to me. Note that a weaker randomizing map would merely leave them with a data hiding state, which I suppose corresponds to the facebook status “It’s Complicated.” These jokes are still in focus groups, so please forgive them.
We would like to have unitary designs that have low gate complexity. The main result of this talk is a Clifford-only unitary 2-design that uses 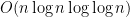


One can construct these 2-designs by writing gates in the form 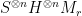

Carl Miller and Yaoyun Shi.
Universal security for randomness expansion. Previous title: Universal security for quantum contextual devices
abstract arXiv:1411.6608
Carl opens his talk by saying that this result has been a goal of the U of M group for the past four years. It then proceeds in suitably epic fashion by looking up the definition of randomness from The Urban Dictionary (highlight: “A word often misused by morons who don’t know very many other words.”) and moving onto modern cryptographic standards (skipping, though, this gem).
This talk follows the research program laid out by Colbeck in 2006, where he suggested that one might take the output of some CHSH games, verify that the winning probability is higher than the optimal classical value, and then apply a deterministic extractor. Difficulties here involve quantum side information, information locking, and the other nuisances that composable security was invented to address. Vazirani-Vidick showed in 2011 that this was possible if in the honest case the Bell inequality is violated optimally, last QIP Miller and Shi showed it worked with some not-quite-perfect value of the CHSH game and the current result extends this to any beyond-classical value of the game.
One the key technical ingredients is a new uncertainty principle.
We will not fully do it justice here. Roughly it is as follows. Define
![Y = \text{tr} [\rho_+^{1+\epsilon} + \rho_-^{1-\epsilon}] / \text{tr}[\rho^{1+\epsilon}]](https://s0.wp.com/latex.php?latex=Y+%3D+%5Ctext%7Btr%7D+%5B%5Crho_%2B%5E%7B1%2B%5Cepsilon%7D+%2B+%5Crho_-%5E%7B1-%5Cepsilon%7D%5D+%2F+%5Ctext%7Btr%7D%5B%5Crho%5E%7B1%2B%5Cepsilon%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![X = \text{tr} [\rho_0^{1+\epsilon}] / \text{tr} [\rho^{1+\epsilon}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Ctext%7Btr%7D+%5B%5Crho_0%5E%7B1%2B%5Cepsilon%7D%5D+%2F+%5Ctext%7Btr%7D+%5B%5Crho%5E%7B1%2B%5Cepsilon%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
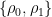
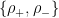

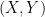
The proof uses the “uniform convexity of the 
At one point Carl says: “By an inductive argument (which actually takes 20 pages), we see that…”
The result can then be generalized beyond X-Z measurements to any pair of non-commuting measurements.
Now what about totally untrusted devices? These too can be forced, using a VV-like approach, to act in a way as though they are performing non-commutative measurements.
This can be generalized even further to Kochen-Specker inequalties and contextuality games, modulo some mild assumptions on how the device works.
open problems: what resources are used? This uses a linear amount of entanglement, for example. For any experimentalists watching (for whom entanglement is scarce and randomness abundant), this part of the talk must sound funny.
Neil J. Ross and Peter Selinger.
Optimal ancilla-free Clifford+T approximation of z-rotations (Plenary Talk)
abstract arXiv:1403.2975
Optimal ancilla-free Clifford+T approximation of z-rotations (Plenary Talk)
abstract arXiv:1403.2975
Solovay-Kitaev was all about geometry, but recently the field of quantum compiling has shifted to algebraic number theory, following the path-breaking 2012 paper by Kliuchnikov, Maslov, and Mosca.
Some number theory: In the ring ![\mathbb{Z}[\sqrt{2}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Csqrt%7B2%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
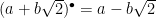
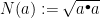
Applying the bullet operation (a Galois automorphism of the number field) to a compact interval yields a discrete unbounded set. The 1-d grid problem is, given finite intervals 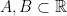
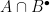

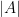

![\mathbb{Z}[2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B2%5D&bg=ffffff&fg=000&s=0&c=20201002)
The 2-d grid problem: Now we consider ![\mathbb{Z}[\omega]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Comega%5D&bg=ffffff&fg=000&s=0&c=20201002)
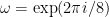
Main Theorem: Let A and B be two convex sets with non-empty interior. There is is a grid operator 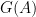
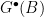
Theorem [Matsumoto-Amano ’08]
Every Clifford + T single-qubit operator W can be uniquely written in the form
W = (T | eps) (HT | SHT)* C,
where C is a Clifford.
Exact synthesis of the Clifford+T operators was solved by Kliuchinikov, Maslov, and Mosca. If You have 
![\frac{1}{2^{k/2}} \mathbb{Z}[\omega])](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%5E%7Bk%2F2%7D%7D+%5Cmathbb%7BZ%7D%5B%5Comega%5D%29&bg=ffffff&fg=000&s=0&c=20201002)

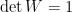
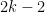
The upshot of this is that if you have a factoring oracle then the algorithm gives circuits of optimal T-count. In the absence of such an oracle, then this returns a nearly optimal T-count, namely the second-to-optimal T-count 
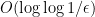
Adam Bouland and Scott Aaronson.
Generation of Universal Linear Optics by Any Beamsplitter
abstract arXiv:1310.6718
Are there any interesting sets of beamsplitter-type quantum gates that don’t generate either only permutation matrices or arbitrary unitaries? The main result is that if one has a two-level unitary of determinant 1 and with all entries non-zero, then it densely generates SU(m) or SO(m) for 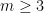

Isaac Kim.
On the informational completeness of local observables
abstract arXiv:1405.0137
2014 has seen some of the most exciting news for quantum conditional mutual information since strong subadditivity.
The goal of this talk is to try to find a large class of interesting states 
At one point in the intro, Isaac says that a point is “…for the experts, err, for the physicists.” Then he remembers who his audience is. Later he says “for this audience, I don’t have to apologize for the term ‘quantum conditional mutual information'”.
This talk proposes a class 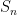


Isaac first reviews the approach to matrix product state tomography, which uses the parent Hamiltonian of a matrix product state to show that any (injective) MPS is completely determined by a local set of observables. This result is a generalization of the MPS tomography result to higher dimensions, but with the important difference that there is no need for a global wavefunction at all!
The main result, roughly speaking, is that there exists a certificate 

Local density matrices can (approximately) reconstruct the global state. Previously this was done assuming that the global state is a low-bond-dimension MPS. But that’s in a sense circular because we have to make a (strong) assumption about the global state. This work allows us to do this purely using local observables. Awesome.
The talk proceeds by giving a reconstruction procedure by which a global state 
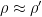
Theorem 1: If
and
then
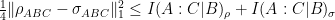
This is nice, but the upper bound depends on global properties of the state. (Here we think of AB and BC as “local” and ABC as “global.” Don’t worry, this will scale well to
To proceed we would like to upper bound the QCMI (quantum conditional mutual information) in terms of locally observable quantities. This is a straightforward but clever consequence of strong subadditivity. Specifically
for any system 
For judicious choice of regions, and assuming a strong form of the area law conjecture (
We can then build up our reconstruction qubit-by-qubit until we have covered the entire system.
Applications:
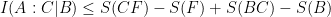
- quantum state tomography: Measure local observables and check the locally computable upper bound. If the latter is small, then the former contains sufficient information to reconstruct the global wavefunction.
- quantum state verification: Similar except we want to just check whether our physical state is close to a desired one
Bartek Czech, Patrick Hayden, Nima Lashkari and Brian Swingle.
The information theoretic interpretation of the length of a curve
abstract arXiv:1410.1540
At ultra-high energies, we need a theory of quantum gravity to accurately describe physics. As we move down in energy scales, vanilla quantum field theory and eventually condensed-matter physics become relevant. Quantum information theory comes into play in all three of these arenas!
One of the principal claims of this talk is that quantum information is going to be central to understanding holography, which is the key concept underlying, e.g., the AdS/CFT correspondence. Quantum gravity theories in negatively curved spacetimes (saddle-like geometries) seem to have a duality: one Hilbert space has two theories. The duality dictionary helps us compute quantities of interest in one theory and map the solutions back to the other theory. It turns out that these dictionaries often involve computing entropic quantities.
A funny feature of AdS space is that light can reach infinity and bounce back in finite time! This acts just like boundary conditions (at infinity) and simplifies certain things. Inside the bulk of AdS space, geodesics are (in the Poincare disk model) just circular arcs that meet the boundary at right angles. When there is matter in the bulk, these get deformed. We’d love to be able to interpret these geometric quantities in the bulk back in the CFT on the boundary.
The Ryu-Takayanagi correspondence links the length of a geodesic in the bulk with the entanglement entropy in the CFT on the boundary. This can be related (using e.g. work by Calabrese & Cardy) to the central charge of the CFT. A really neat application of this correspondence is a very simple and completely geometric proof of strong subadditivity due to Headrik and Takayanagi (with the important caveat that it applies only to a restricted class of states, namely those states of CFTs that have gravity duals).
The new result here is to generalize the Ryu-Takayanagi correspondence to general curves, not just geodesics. The main result: there is a correspondence between the length of convex curves in the bulk and the optimal entanglement cost of streaming teleportation communication tasks that Alice and Bob perform on the boundary.
Thank you Steve, for this fine live-blogging, which is valuable to everyone who reads it (including me). On Scott Aaronson’s weblog I have posted an appreciation of the Pontifical live-blogging, in particular the review of Isaac Kim’s “On the informational completeness of local observables” (arXiv:1405.0137).
It would be terrific (as it seems to me) if the large-and-lively readership of Shtetl Optimized were better tuned-in to the deep-and-broad topics of The Quantum Pontiff. Please allow me to express my appreciation of and gratitude toward both forums.
Thank you, Steve (especially) for your outstanding personal commitment and sustained professional efforts in so ably live-blogging QIP 2015.
Thanks for the recognition, but Charlie and especially Aram have been helping as well! I just posted this day’s live-blog, but it was all three of us that co-wrote it.
BTW, day 5 is coming soon… we just have to clean up the latex a bit. We’ll also write about the business meeting.
Thank you Steve; a four-fold appreciation of the Pontiffs now appears as a comment on Shtetl Optimized. Coverage of the final day of QIP 2015 — in particular the closing remarks and any concluding observations by the Pontiffs — would be appreciated gratefully by many (including me).
Thanks Aram for blogging about the Miller-Shi result. The “uniform convexity” is very useful and I look forward to learning about your new application with Fernando. Just to respond to your comment on the open problem about entanglement.If the entanglement would have to be prepared in advanced then it’d indeed be not so encouraging. But in the protocol we analyzed, the device components can exchange information in-between rounds of games. Thus they need only to store a single qubit, long enough for playing one game. The open problem would make sense only when we forbid such kind of communication. I have to say I’m not completely sure about its real world relevance (perhaps some experimentalists could chime in), but perhaps in some hopefully not so distant future we know better how to store entanglement for a longer time and long-distance communication remains difficult (or in some paranoid situations that it wouldn’t be possible). Then we have good reason to minimize entanglement without communication. But in any case, it is a great theoretical question addressing what quantity determines the extractible bits in an untrusted quantum device.