It’s times like these that I wished I’d kept my old Dell desktop around (hell I wish I’d kept my TRS-80 CoCo and my Apple IIGS!)

Won because I know my children’s literature 🙂

O brave new quantum world!
It’s times like these that I wished I’d kept my old Dell desktop around (hell I wish I’d kept my TRS-80 CoCo and my Apple IIGS!)
Won because I know my children’s literature 🙂
My last trip to Canada for a CIFAR conference was….interesting. This time I’m in Toronto for the quantum computing CIFAR meeting and I’m happy to report that the meeting is full of people who mostly believe quantum theory and who also happen to be doing very interesting work. My favorite talk, because I’m biased to this line of work, was Robert Raussendorf’s talk on the universality for measurement-based quantum computing on the 2D AKLT state (work he did with Tzu-Chieh Wei and Ian Affleck. The authors are TAR, heh.) It was also interesting to hear the state of position based quantum cryptography. It seems that history (bit commitment) is repeating itself? Marcin Pawlowski also gave a very neat derivations of Bell inequalities that I’d never seen….using an Escher drawing!
Some photos. First of all it was not clear if the pain the sign below was related at all to quantum information processing:
 And then there was what some would consider computer scientist’s heaven:
And then there was what some would consider computer scientist’s heaven:
 I did manage to have a beer and write some equations in said bar. I’m certain they are correct.
I did manage to have a beer and write some equations in said bar. I’m certain they are correct.
Two observations from yesterdays New York Times article about quantum computing (Moving Toward Quantum Computers.)
First, the drawing accompanying the article (here) is interesting to me. I wonder where they got the idea for it and whether this idea involved Q*bert, color codes, or topological codes? Or was it just the same old: we have no idea how to draw a quantum computer, so lets just make a cool looking graphic?
Second, I find this sentence fascinating: “D-Wave has built a system with more than 50 quantum bits, but it has been greeted skeptically by many researchers who believe that it has not proved true entanglement.” Emphasis mine. Okay I find it fascinating not because of the debate about the quantum nature of D-wave’s machine, but for its language. If there is “true” entanglement, what is “false” entanglement? Further for some reason I can’t quite pen down the sentence strikes me as awkward. In particular it feels like it needs to be something more like “that is has not proved that its system possess real entanglement.” (Yes I understand the sentence, yes I’m not good at reading comprehension, and yes I’m beyond pedantic.) Am I the only one having a hard time parsing this sentence
Next week, Wed-Fri, I’ll be at University of Maryland for a workshop titled “From Quantum Information and Complexity to Post Quantum Information Security” sponsored by the Joint Quantum Institute (JQI), NIST, and the University of Maryland. This should be a lot of fun: my talk is titled “Help! There is a Computer in My Physical System!” and the program looks to have some fun talks as well. And…here is the important part…it looks like I will have about three extra hours to spend in downtown D.C. (I’m flying out of DCA). This is amazing because, while I fly in to Washington D.C. a lot, I never ever seem to have any extra time in my schedule when visiting. So, if you had three hours in Washington D.C. what would you do? (Cue Libertarian jokes about destroying the government in 3,2,1…)
A while back Michael Nielsen posted a comment in one of my blog posts that I’ve been thinking a lot about lately:
Re your last two paragraphs: a few years ago I wrote down a list of the ten papers I most admired in quantum computing. So far as I know, not a single one of them was funded, except in the broadest possible sense (e.g., undirected fellowship money, that kind of thing). Yet the great majority of work on quantum computing is funded projects, often well funded. My conclusion was that if you’re doing something fundable, then it’s probably not very interesting. (This applies less so to experimental work.)
This, of course, is quite a depressing idea: that the best work is funded at best indirectly by the powers that be. But it hadn’t occurred to me until much more recently that I, as someone who regularly applies for funding can do something about this problem: “My good ideas (all two of them)? Sorry Mr. Funding Agency, I’m not going to let you fund them!” And there is a bonus that if you submit something to an agency and they won’t fund it: well you can live under the illusion that you are doing might make the list of really important research.
Actually I’ve very proud of one research proposal I wrote that got rejected. The reviewers said “this work raises interesting questions” and then “but it’s just too crazy for us.” I mean it sucks to get rejected, but if you’re getting rejected because you’re just too crazy, well then at least you’re eccentric! (A similar story was my dream of becoming a ski bum after getting my Ph.D. in theoretical physics. I mean anyone can be a liftie, but a liftie with a degree in physics? Now that would set you apart! Lifties with Ph.D.s in physics please leave a note in the comment section of this blog 🙂 )
The NRC graduate school ranks are due out tomorrow, September 29. For those who don’t know, the last NRC ranking was in 1995 and the latest is much delayed (I.e. the “data” such as it is is already out of date.) Departments have been given access to the data for a week now but have been under embargo. As a blogger it is a moral imperative to search the inter tubes for leaks of this data. Surprisingly there has been little leaked, but today I’m proud to say that my own UW, while not technically breaking the embargo (okay maybe they have :)) has some info out about their forthcoming rankings. Now I’m probably definitely biased but I can pretty safely say that the UW CS ranking is off by a bit:
The NRC assessment of UW Computer Science & Engineering is based on clearly erroneous data. The assessment is meaningless, and in no way representative of the accomplishments of UW CSE. Errors in the data affect (at least) UW CSE, many other computer science programs nationally, and many programs in other fields at the University of Washington.
During the week of September 19th, NRC provided pre-release access to its long-delayed “Data-Based Assessment of Research-Doctorate Programs in the United States,” scheduled for public release during the week of September 26th.
We, along with colleagues in other computer science programs nationally and colleagues in programs in other fields at the University of Washington, quickly discovered significant flaws of three types in NRC’s data:
- Instances in which the data reported by NRC is demonstrably incorrect, sometimes by very substantial margins.
- Instances in which the accuracy of the data cannot easily be checked, but it does not pass even a rudimentary sanity check.
- Instances in which institutions interpreted NRC’s data reporting guidelines differently, yielding major inconsistencies.
Here are three specific examples affecting UW CSE:
- Due to difficulty in interpreting NRC’s instructions, NRC was provided with an incorrect faculty list for our program – essentially, a list that included anyone who had served as a member of a Ph.D. committee. In 2006 (the reporting year), UW CSE had roughly 40 faculty members by any reasonable definition. In the NRC study, our “total faculty” size is listed as 91 and our “allocated faculty size” (roughly, full time equivalent) as 62.5. A large number of these “additional faculty” were industrial colleagues – whose “academic records” (including grants, publications, and awards) were quantitatively evaluated by NRC as if these individuals were full members of our faculty. Since faculty size is the denominator in many measures computed by NRC, you can imagine the result – clearly erroneous.
- NRC reports UW CSE with 0% of graduate students “having academic plans” for 2001-05 (the reporting period for this measure). In fact, 40% of our graduating Ph.D. students took full-time faculty positions during this period. We are one of the top programs nationally in producing faculty members for major departments; in recent years our graduates have taken faculty positions at Berkeley, CMU, MIT, Princeton, Cornell, Wisconsin, Illinois, Michigan, Penn, Waterloo, Toronto, WashU, UCSD, Northwestern, UCLA, UBC, Maryland, Georgia Tech, UMass-Amherst, and many other outstanding programs. NRC obtained this number from an outside data provider; it’s clearly erroneous.
- NRC reports UW CSE as having 0.09 “awards per allocated faculty member.” The erroneous faculty count is not sufficient to explain this, given that our faculty includes 14 ACM Fellows, 10 IEEE Fellows, 3 AAAI Fellows, 14 Sloan Research Fellowship recipients, a MacArthur Award winner, two NAE members, 27 NSF CAREER Award winners, etc. We don’t know where NRC obtained this data, but it’s clearly erroneous.
The University of Washington reported these issues to NRC when the pre-release data was made available, and asked NRC to make corrections prior to public release. NRC declined to do so. We and others have detected and reported many other anomalies and inaccuracies in the data during the pre-release week.The widespread availability of the badly flawed pre-release data within the academic community, and NRC’s apparent resolve to move forward with the public release of this badly flawed data, have caused us and others to take action – hence this statement. Garbage In, Garbage Out – this assessment is based on clearly erroneous data. For our program – and surely for many others – the results are meaningless.
It’s the paper dance, done automagically (one of the authors is a Dancing Machine, the other, not so much):
arXiv:1009.2203 [scirate arxiv]
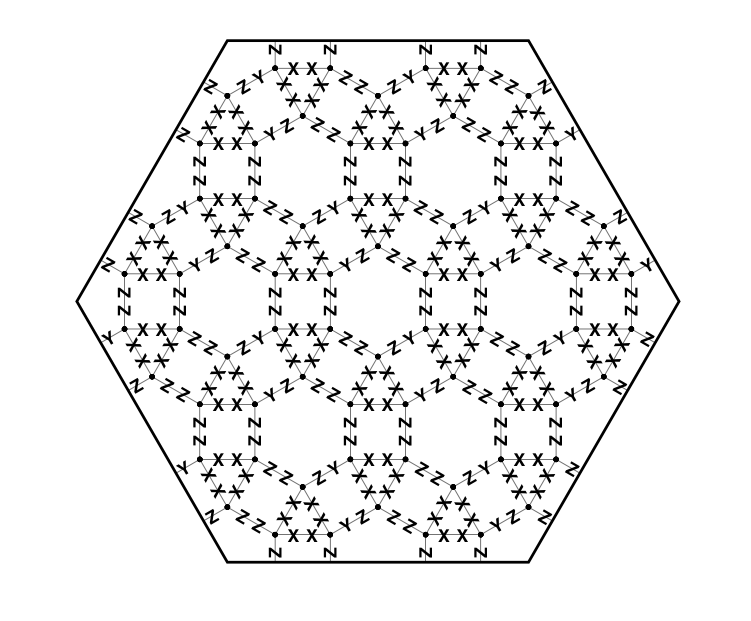
Automated searching for quantum subsystem codes by Gregory M. Crosswhite, Dave Bacon
Quantum error correction allows for faulty quantum systems to behave in an effectively error free manner. One important class of techniques for quantum error correction is the class of quantum subsystem codes, which are relevant both to active quantum error correcting schemes as well as to the design of self-correcting quantum memories. Previous approaches for investigating these codes have focused on applying theoretical analysis to look for interesting codes and to investigate their properties. In this paper we present an alternative approach that uses computational analysis to accomplish the same goals. Specifically, we present an algorithm that computes the optimal quantum subsystem code that can be implemented given an arbitrary set of measurement operators that are tensor products of Pauli operators. We then demonstrate the utility of this algorithm by performing a systematic investigation of the quantum subsystem codes that exist in the setting where the interactions are limited to 2-body interactions between neighbors on lattices derived from the convex uniform tilings of the plane.
With pictures:
and with code to boot: http://github.com/gcross/CodeQuest/downloads.
These are all very selfish, so sue me. Readers who don’t like navel gazing should stop reading now and make sure not to gaze at their own navels. Things I’ve done recently that have improved my life (brought to you by the word “shrill”):
Scienceblogs, the science network that was my old (where “old” = “a few days ago”) haunt, is in revolt. Okay, well maybe the network is not in revolt, but there is at least a minor insurgency. Yesterday, the amazing force of blogging known as @Boraz, left the network (be sure you have more than a few minutes if you are going to read Bora’s goodbye letter.) Today, the biggest fish of them all, PZ Myers has gone on strike (along with other Sciencebloggers.) Numerous other bloggers have also jumped ship (a list is being kept by Carl Zimmer here.) This is both sad, as I personally think the Scienceblogs network does contribute significantly to spreading the joys and tribulations of science, but also a bit exciting for, as Dave Munger points out, this also represents the prospect of new networks arising and hopefully pushing the entity that is known as the science-blogosphere forward.
I myself am not much of a blogger. What I write here is for my own personal amusement (so if you don’t like it, well I don’t give a damn, thankyouverymuch) and, frankly, to distract my fellow quantum computing researchers from getting any work done (ha!) I do enjoy writing (literature major, you know) and also enjoy trying to write coherently about science, and sometimes, as a consequence, I get read by people who aren’t here just to hear about the latest and greatest in quantum channel capacities. That’s great, but I don’t really consider science blogger as my defining characteristic (my self image, such as it is, is more in the line of a hack who has somehow managed to remain in science—despite being almost a decade out of graduate school without a tenure track position due in large part to being stubborn as hell. But that’s another story.)
But, even though I don’t consider myself very bloggerrific, having had a seat at the Scienceblogs table gave me an up front look at, to use a silly term, new media, and in particular at the notion of a science network. So to me, following Munger’s post, the interesting question is not what will become of Scienceblogs in its current form, but how will the entities we call science networks evolve going forward. Since there are a large number of Sciencebloggers jumping ship, it seems that now would be a good time for a new media science mogul to jump into the fray and scoop up some genuinely awesome bloggers. So the question is, what should a science network look like?
To begin, I can start with Pieter’s comment a few days ago:
…I never fully understood the need for successful bloggers to join an umbrella organization. Did you get more readers when you moved to Pepsiblogs (good one!)?
That is exactly what I thought when I was asked, clearly by some clerical error, to join Scienceblogs! Having joined, I can say that yes, it did increase my blog traffic. But I think a science network also adds something else.
First of all, there is the fact that there is a front page which contains significant “edited” content. It is edited in the sense that the powers that be have a large say in selecting what appears there in a highlighted mode. This great because even the best bloggers, I’m afraid, generate a fair amount of posts which aren’t too exciting. A discerning eye, however can grab the good stuff, and I regularly go to the front page to see what exciting is being blogged about. I’m not sure that the front page of Scienceblog is the best way of providing an edited version of a blog network, but I do think that it is heading in the right direction. So in thinking about moving forward, I wonder how one could change this editing and give it more value. For instance, is the fairly static setup of the front page the right way to go, or should there be a more dynamic front page?
Another important property of a science network is in building discussion, and by discussion I don’t just mean a bunch of people agreeing with each other. For example, Scienceblogs has a “buzz” where articles on a featured topic are posted on the front page. Sometimes this content presents a unified view of a topic, but mostly you get a terrific variety of opinions about a subject. Now I won’t argue that this diversity of opinion is huge: for instance you aren’t likely to find the Christian view on topological insulators, but you are likely to get the opinion of a large number of scientists or science journalists from a variety of areas. This solves, for me, one of the worst problems with my blog reading: only following blogs for which I am predetermined to agree with the blogger. Further this content gives rise to a genuine discussion among the bloggers in that they actually will read what others have written as opposed to just sitting on an isolated island (okay well I rarely read what even I’ve written, hence the horrible typos and grammatical gaffs that liter my writing.)
Third a science network like Scienceblogs serves as a proxy for a certain amount of quality. Despite me trying to bring this quality down, I would say that some of the best science bloggers around have or have had a blog at Scienceblogs and this lets the network serve as a proxy for having to read a bunch of blog posts to see if the person has something interesting to say, or whether they are not worth your time.
So those are at least some of the reasons that a science network is good. I must say, in thinking about these reasons, however, that I can’t completely convince myself that these amount to enough to justify the science networking idea. Many high quality bloggers get along just fine without such a network.
Which brings me to the real subject of this post: how would I redesign Scienceblogs?
Well the first thing that comes to mind is better tech support. Okay, just kidding. Kind of.
Actually I do think there is a valid point in this dig at tech support. One of the hardest things for me while I was at Scienceblogs was not being able to dig around and modify my blog in the sort of way I can do on my own hosted server. Why is this important? Well, for example, Scienceblogs does not currently have a mobile version of the website. (Mea culpa: at one point, back when I was writing iPhone apps, I emailed the powers that be at Scienceblogs asking if they wanted me to design an iPhone app for them. I got crickets back in response. Later this came up in discussion among Sciencebloggers and the powers that be emailed me asking for more details. This was in the middle of the impending arrival of baby Pontiff, so I never followed back up on this. I feel bad for not doing this, but it seems that if the management was really serious about this they could have pursued numerous other, um, really qualified people. Note that it took me about 30 minutes to get a mobile read version of my blog setup when I moved back here, and yes this is different than an iPhone app.) But more importantly, technology has that important property that it is constantly changing. Anyone who wants to build a network of science blogs should probably seriously consider that the infrastructure they are building will be out of date every few years or so and need major upgrades at a fairly high rate.
For instance, Scienceblogs should have been among the first to offer an iPhone app, an Android app, an iPad app. Scienceblogs should think of ways to incorporate its tweeting members: as it is, as far as I know, Scienceblogs doesn’t even keep a list of its members who tweet. Scienceblogs, a network about science, doesn’t even have LaTeX support for heaven’s sake, let alone, as far as I can tell, plans for how things like html5 will change what one can do on a website. What will happen to Scienceblogs when technology adapts? Will it adapt too?
So I think, if I were going to start a new science network I would start with an incredibly dedicated hacker. A quickly adaptable platform is a prereq and if you don’t start with a good base, well then you are just going to be out of date pretty quickly.
But of course there is more to a platform than just the tech behind the scenes. There is also the content. I have a lot of admiration for the people who have been the behind the scenes editors at Scienceblogs and I think this is part of the network that worked the best. I do wonder, however, if they have enough editorial control: that is it would seem to me that they should have an even more expansive roll in the network. And it’s not clear to me that there should be as large of a separation between their magazine Seed and the Sciencebloggers. I would wager that many people don’t even know that Scienceblogs is related to Seed or that Seed exists at all. And here is where I think one needs to get a little radical. Seed should (as roughly suggested by Bora), I think, give up it’s print magazine and fold Seed into Scienceblogs. High quality traditional media pieces like those Seed produces are great. So why can’t they be part of the network in an integrated way?
Well these are just my silly initial thoughts about re-imagining science networks, when I should be busy changing diapers. And certainly I don’t know what I’m talking about. But read the disclaimer in the upper right of this blog. So don’t say I didn’t warn you!
Some human resources departments have a title called “Generalist” who is someone that can basically handle a wide variety of issues. Academia, on the other hand, has a title called “Professor” who more often than not is an expert in one particular narrow area of their already fairly narrow profession. There are very few professors who are generalists, though I don’t think this is of their own choosing, but is the product of a lot of culture and practicality (expertise is necessary for advancement of the academic’s field.)
I was thinking about this the other day, and mulling over how I think I’m might be more of a generalist than a specialist (or at least I’m a lousy dilettante), when it occurred to me that perhaps this is the reason why I ended up in quantum computing. To the outside world quantum computing people are often characterized by “Oh they’re a quantum person.” I’ve heard exactly that phrase (especially when it comes to hiring decisions 🙁 )
But let’s think a bit about what that means. Quantum theory is an uber-theory of physics, sitting squarely at the base of theoretical physics. Computing is…well….gigantic. It is a joke that to form a research area in quantum computing you simply go to the dictionary of fields in computing and affix a big fat “quantum” in front of it. It may be a joke, but it’s very much true.
For example, I have worked in quantum error correction, quantum algorithms, universal quantum computing, simulation of quantum correlations, quantum foundations (Bell inequalities with communication), quantum computing in bizarre models of physics, adiabatic quantum protocols, and matrix product states algorithms for simulating quantum physics. And I’m a lazy bastard with a short publication list. A further example of this is the last paper I put up on the arxiv, arXiv:1006.4388 with co-authors Isaac Crosson and Ken Brown. In that paper we discuss essentially a statistical physics result and, along with connecting it to a model of computing, we also tie our work to a fundamental complexity class. Fun stuff! (Though hard to find an appropriate journal.)
I’ve often said that one of the great things about working in quantum computing is that I get to see all sorts of talks, from hard-core experimental physics to pie in the sky theoretical computer science. It only recently occurred to me that this is, apparently, is my own private way of getting to pretend to be a generalist. Which is to say, it used to bug me when people said “oh that Quantum Pontiff he’s just a quantum dude” (quantizing Bishops left and right, well mostly right!) But now I take it as a great protective shield, keeping me from bolting a system that favors single minded expertise over any broader approach.
{kind=link}