
I’ll try to post something less boring soon, but for now wanted to mention that the schedule for QIP is now online, and that early registration ends on Dec 1.
QIP 2015??
The following is a public service announcement from the QIP steering committee. (The “service” is from you, by the way, not the committee.)
Have you ever wondered why the Quantum Information Processing conference seems to travel everywhere except to your hometown? No need to wonder anymore. It’s because you haven’t organized it yet!
The QIP steering committee would like to encourage anyone tentatively interested in hosting QIP 2015 to register their interest with one of us by email prior to QIP 2013 in Beijing. The way it works is that potential hosts present their cases at this year’s QIP, there is an informal poll of the QIP audience, and then soon after, the steering committee chooses between proposals.
Don’t delay!
By the way, QIP 2014 is in Barcelona, so a loose tradition would argue that 2015 should be in North (or South!) America. Why? Some might say fairness or precedent, but for our community, perhaps a better reason is to keep the Fourier transform nice and peaked.
QIP 2013 accepted talks, travel grants
The accepted talk list for QIP 2013 is now online. Thomas Vidick has done a great job of breaking the list into categories and posting links to papers: see here. He missed only one that I’m aware of: Kamil Michnicki’s paper on stabilizer codes with power law energy barriers is indeed online at arXiv:1208.3496. Here are Thomas’s categories, together with the number of talks in each category.
- Ground states of local Hamiltonians (4)
- Cryptography (3)
- Nonlocality (6)
- Topological computing and error-correcting codes (4)
- Algorithms and query complexity (6)
- Information Theory (9)
- Complexity (2)
- Thermodynamics (2)
Other categorizations are also possible, and one important emerging trend (for some years now) is the way that the “information theory” has broadened far beyond quantum Shannon theory. To indulge in a little self-promotion, my paper 1210.6367 with Brandao is an example of how information-theoretic tools can be usefully applied to many contexts that do not involve sending messages at optimal rates.
It would be fascinating to see how these categories have evolved over the years. A cynic might say that our community is fad-driven, but instead I that the evolution in QIP topics represents our field working to find its identity and relevance.
On another note, travel grants are available to students and postdocs who want to attend QIP, thanks to funding from the NSF and other organizations. You don’t have to have a talk there, but being an active researcher in quantum information is a plus. Beware that the deadline is November 15 and this is also the deadline for reference letters from advisors.
So apply now!
Programs announced for AQIS'12 and Satellite Workshop
The accepted papers and schedule for the twelfth Asian Quantum Information Science conference, in Suzhou, China 23-26 August, have been announced. It will be followed by a satellite workshop 27-28 August on quantum Shannon theory in nearby Shanghai. Unfortunately we probably won’t be live-blogging these events, due to most of the pontiffs being elsewhere.
QIP 2013
QIP is in Beijing this time from Jan 21-25, 2013. And the call for papers has just been posted.
- Submission deadline for talks: October 5, 2012
- Notification for talk submissions: November 9, 2012
- Submission deadline for posters: November 16, 2012
- Notification for poster submissions: November 26, 2012
The submission guidelines continue to slowly evolve. Last year called for “2-3 pages in a reasonable font” and this year is a somewhat more precise “up to 3 pages in 11pt font with reasonable margins, not including references”. From my experience on PCs in the past (I’m not on the PC this year, though), I’ll mention that these short submissions sometimes are very good, but sometimes aren’t addressed at the key questions that the PC will want to consider, such as:
- What is the key result?
- How does it compare with previous work on this subject? And how does it fit into the broader context of other research?
- What are the technical innovations necessary to achieve it, and possibly to overcome obstacles that stopped people before?
- (If the topic area is unconventional, or the submission is about a newly invented problem.) Why is this a good area for people to study?
These are kind of basic, but it’s surprising how many good results are undermined by not explaining these points well.
Another feature of the CFP to notice is that authors are strongly recommended to link to a version of their paper on their arxiv, or to include a long version of their paper as an attachment. The idea here is that if a result is not ready to go on the arxiv, then it’s less likely to be correct. There was debate about making it mandatory to post a full version on the arxiv, but this idea was dropped because many people felt that this way we might miss out on the freshest results.
A related concern is about keeping the barriers to submitting to QIP low. Of course, travel is always a barrier, but hopefully we shouldn’t waste a lot of people’s time with elaborate submission requirements if we expect the acceptance rate to be around 20%. I think the current requirements are reasonable, as long as people don’t stress too much about making a special short version, e.g. by writing something informal about why the paper should be accepted and referring liberally to the long version instead of trying to pack as much as possible in three pages. But I can imagine other systems as well. What do you think about the way QIP is being run right now?
QIP 2012 videos!
The long awaited videos from QIP 2012 are now online.
Somewhat. If you see a video that you want that isn’t online, then tell the speaker to sign the release form! I’m looking at you Bravyi, Greiner, Landahl and Popescu! (And others.)
If you haven’t seen them before, then you should check out the talks by Haah (on 3-d local stabilizer codes) and Arad (on an improved 1-d area law).
QIP 2012 wrap-up
Here, in one place, are all the links to our QIP blogging. Here is the program for the conference.
Also, an editorial note: even though the posts say they are posted by so-and-so, in fact we did them all pretty much jointly, typing simultaneously into a google document. This joint editing worked really well; perhaps if google documents implements latex in a nice way, it might just realize Nielsen’s dream.
QIP 2012 Day 5
The quantum pontiff brains have reached saturation.

Eric Chitambar, Wei Cui and Hoi-Kwong Lo:
Increasing Entanglement by Separable Operations and New Monotones for W-type Entanglement
These results demonstrate a large quantitative gap between LOCC and SEP for a particular task called random EPR distillation. Therefore, SEP may not always be a good approximation for LOCC. They also demonstrate entanglement monotones that can increase under SEP, the first known examples with analytic functions. They also show that LOCC is not a closed set of operations, so optimal LOCC protocols may not exist.
Recall how LOCC works: Alice and Bob share a bipartite pure state 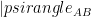

So now we know that SEP and LOCC are not equal, but how non-equal are they? That is, can we quantify the gap between the two classes? There is some previous work, such as Bennett et al., who showed that the mutual information for state discrimination had a gap of at least 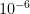
SEP is precisely the class of operations that cannot create entanglement out of nothing, but if we seed things with a little bit of entanglement, can we use SEP to increase the entanglement? We need to define some LOCC monotone to make this a meaning statement.
Surprisingly, yes! There are entanglement transforms that work in SEP but not LOCC, and therefore entanglement monotones (but artificial ones) that can increase under SEP but not LOCC. To give some intuition, though, here is a non-artificial task.
Random-party distillation of W-class states:
An N-partite W-class state looks (up to local unitary rotation) like

It’s a good class of states to study because they are only parameterized by N real numbers (as opposed to 2N), it is easy to characterize how the states transform under local measurements, and it is closed under SLOCC. See this paper by Kintas and Turgut for a review of the properties of W-class states.
Here is a nice example, due to Fortescue and Lo. Start with a tripartite W state, and have each party perform the measurement 

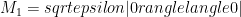
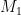
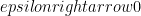
This can be generalized by using local filtering to first (probabilistically) map a W-class state to one with 
The fact that they establish an entanglement monotone means they get an awesome corollary. There is a parameter 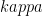
LOCC is not closed!
Here is a great open question (not in the talk): Find a similar monotone that describes data hiding, for example to improve the analysis of these states.
For the multipartite setting, there are a few more ideas. There is a single-copy “combing transformation” (analogous to the one of Yang & Eisert), which transforms all the entanglement to bipartite entanglement shared with Alice. Again SEP is better than LOCC, in ways that can be quantified.
Some open problems:
- What about the case of
W-states? They have some partial results, but it still remains open.
- Can the gap between SEP and LOCC be increased arbitrarily?
- Can one apply these ideas to other entanglement classes?
- Do there exist similar phenomena in bipartite systems?
- How much entanglement is required to implement SEP operations?
Rodrigo Gallego, Lars Erik Würflinger, Antonio Acín and Miguel Navascués:
Quantum correlations require multipartite information principles
(merged with)
An operational framework for nonlocality
Normally, we define “3-partite entanglement” to mean states that are not separable with respect to any bipartition; equivalently, they cannot be created by LOCC even if two parties get together. But this definition can be dangerous when we are considering nonlocality, as we will see below.
Nonlocality is a resource for device-independent information protocols. Define a local joint probability distribution to be one which satisfies 
Nonlocality is often described in terms of boxes that mimic measurements on entangled states. But entanglement can also be manipulated, e.g. by LOCC. What is the analogue for boxes? Are their variants of entanglement swapping, distillation, dilution, etc? In most cases, when we make the boxes stronger, the dynamics get weaker, often becoming trivial.
They define a new class or operations called WPICC, which stands for something about rewirings and pre- and post-processing (note that non-local boxes can be rewired in ways that depend on their outputs, so their causal structure can be tricky). WPICC are the operations which map local joint probability distributions to local joint probability distributions, and shouldn’t be able to create nonlocal correlations; indeed, we can use them to define nonlocal correlations, just as entanglement is defined as the set of states that can’t be created by LOCC.
However, with these operations, operations on two parties can create tripartite nonlocality, so this approach to defining nonlocality doesn’t work.
Instead, define a box to be tripartite nonlocal if it doesn’t have a TOBL (time-ordered bilocal) structure, meaning a Markov-like condition that’s described in the paper.
Moral of the story? If you want a sensible definition of tripartite correlations, then beware of operational definitions analogous to LOCC, and focus on mathematical ones, analogous to SEP.
Martin Schwarz, Kristan Temme, Frank Verstraete, Toby Cubitt and David Perez-Garcia:
Preparing projected entangled pair states on a quantum computer
There are lots of families of states which seem useful for giving short classical descriptions of highly entangled quantum states. For example, matrix product states are provably useful for describing the ground states of gapped one-dimensional quantum systems. More generally there are other classes of tensor network states, but their utility is less well understood. A prominent family of states for trying to describe ground states of 2d quantum systems is projected entangled pair states (PEPS). These are just tensor network states with a 2d grid topology. The intuition is that the structure of correlations in the PEPS should mimic the correlation in the ground state of a gapped system in 2d, so they might be a good ansatz class for variational methods.
If you could prepare an arbitrary PEPS, what might you be able to do with that? Schuch et al. proved that an oracle that could prepare an arbitrary PEPS would allow you to solve a PP complete problem. We really can’t hope to do this efficiently, so it begs the question: what class of PEPS can we prepare in BQP? That’s the central question that this talk addresses.
We need a few technical notions from the theory of PEPS. If we satisfy a technical condition called injectivity, then we can define (via a natural construction) a Hamiltonian called the parent Hamiltonian for which the frustration-free ground state is uniquely given by the PEPS. This injectivity condition is actually generic, and many natural families of states satisfy it, so intuitively it seems to be a reasonable restriction. (It should be said, however, that there are also many natural states which don’t satisfy injectivity, for example GHZ states.)
The algorithm is to start from a collection of entangled pairs and gradually “grow” a PEPS by growing the parent Hamiltonian term-by-term. If we add a term to the Hamiltonian, then we can try to project back to the ground space. This will be probabilistic and will require some work to get right. Then we can add a new term, etc. The final state is guaranteed to be the PEPS by the uniqueness of the ground state of an injective parent Hamiltonian.
In order to get the projection onto the new ground state after adding a new term to the Hamiltonian, we can use phase estimation. If you get the right measurement outcome (you successfully project onto the zero-energy ground space), then great! Just keep going. But if not, then you can undo the measurement with the QMA amplification protocol of Marriott and Watrous.
The bound on the run time is governed by a polynomial in the condition number of the PEPS projectors and the spectral gap of the sequence of parent Hamiltonians, as well as the number of vertices and edges in the PEPS graph.
This can also be generalized to PEPS which are so-called G-injective. This condition allows the method to be generalized to PEPS which have topological order, where the PEPS parent Hamiltonian has a degenerate ground space.
Good question by Rolando Somma: What happens if the ground state is stoquastic? Can you get any improvements?
Esther Hänggi and Marco Tomamichel:
The Link between Uncertainty Relations and Non-Locality
The main result: Nonlocality, which means achieving Bell value 
implies an uncertainty relation, namely, the incompatible bases used in the Bell experiment have overlap at most 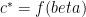
This is a sort of converse to a result of Oppenheim and Wehner.
This has some practical implications: the maximum basis overlap is important for things like QKD and the security of noisy storage, and this result implies that it can be tested robustly by observing a Bell inequality violation.
The kind of uncertainty relation we are interested in is of the form 
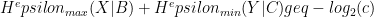
Actually, we need a variant to handle the case that both bases contain a “failure” outcome. This work replaces the maximum overlap 


This parameter 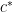
Salman Beigi and Amin Gohari:
Information Causality is a Special Point in the Dual of the Gray-Wyner Region
What is information causality? Essentially the idea that the bound on random access coding should apply to general physical theories in a nonlocal setting. More precisely, Alice has independent bits 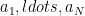
![b in [n]](https://s0.wp.com/latex.php?latex=b+in+%5Bn%5D&bg=ffffff&fg=000&s=0&c=20201002)

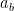
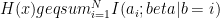
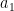


If you look at the details, the key ingredients are the consistency of mutual information (that is, it accurately represents correlations), data processing and the chain rule. These all apply to quantum states as well (hence the quantum random access bound).
Overview of the talk
- connection to Gray-Wyner problem
- generalizing information causality
- connecting to communication complexity.
The Gray-Wyner region is defined as the set of rates 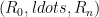
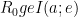

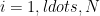
Thm: For any physical theory satisfying the above “key ingredients” plus AMI (accessibility of mutual information, to be defined later), the point
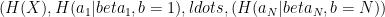
AMI basically means that the mutual information satisfies something like HSW. There is an issue here, which the authors are looking into, with whether the Holevo information or the accessible information is the right quantity to use.
This theorem means that the information causality argument can be generalized: using the same assumptions, we also obtain all of the inequalities that are known to apply to the Gray-Wyner region. Hence the reference in the title to the dual of the Gray-Wyner region; the dual consists of all linear inequalities that are satisfied by the entire Gray-Wyner region.
This improves our understanding of these bounds. It also gives some new lower bounds on the communication cost of simulating nonlocal correlations.
Marcus P. Da Silva, Steven T. Flammia, Olivier Landon-Cardinal, Yi-Kai Liu and David Poulin:
Practical characterization of quantum devices without tomography
Current experimental efforts at creating highly entangled quantum states of many-body systems and implementing unitary quantum gates quickly run into serious problems when they try to scale up their efforts. The dimensionality of the Hilbert space is a serious curse if your goal is to characterize your device using full tomography. For example, the 8-qubit experiment that was done by Häffner et al. in 2005 took a tremendous number of measurements and many many hours of classical post-processing.
But what if you could avoid doing tomography and still get a good characterization of your device? Perhaps you are only interested in one number, say, the fidelity. Can you directly compute the fidelity without going through tomography?
Yes! And you can do it much more efficiently if you are trying to produce a pure quantum state or a unitary quantum gate.
We’ll focus on the case where the target state is a pure state for simplicity. But everything carries over directly to the case of unitary quantum gates with only minor modifications.
The fidelity between your target state 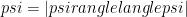
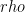

If you expand the expression for F in everybody’s favorite basis, the Pauli basis, then you get









There are a couple of caveats. Sampling from the relevance distribution can in general be a hard problem for your classical computer (though you only have to sample a constant number of times). And the number of repeated measurements that you need to estimate the expectation value might have to scale with the dimension of the Hilbert space.
But there is some good news too. We get a lower bound on tomography which is 
Robin Blume-Kohout:
Paranoid tomography: Confidence regions for quantum hardware
(merged with)
Matthias Christandl and Renato Renner:
Reliable Quantum State Tomography
We consider the setting of a source of quantum states and some measurements, followed by the reconstruction of the quantum state or process. How can we get useful and reliable error bars on the reconstruction?
One problem that you might have when doing a naive linear inversion of a state estimate is that you could have negative eigenvalues on the estimate, which is non-physical. How might you deal with these? One way to do that is to use maximum likelihood estimation (MLE). How might you get an error bar? You could use “bootstrapping”, which is to resample data from the initial estimate to try to estimate the variance. But this can be unreliable: you can even construct counterexamples where it fails miserably! Is there a better way? You could try Bayesian update, where you begin with a prior on state space and then computer a posterior and an error bar. Now everything that you report will depend on the prior, which might be undesirable in e.g. a cryptographic setting. So we need a reliable way to report error bars.
There are some existing methods for producing error bars (e.g. compressed sensing, MPS tomography, and others), but here we are interested in systematically finding the optimal confidence region for an estimate, one that is adapted to the data itself. It is beyond the scope of this work currently to consider also the notion of efficiency; this is an open question.
The main result: They derive region estimators such that the true state is contained in the region with high probability (over the data), and where the size of the region is, in a certain sense, minimal.
Question: how do these relate to the classical statistical notions of confidence region and Baysian credible interval? Tell us in the comments!
The authors use two different techniques to achieve these results. RBK’s results use a likelihood ratio function in the setting of iid measurements. The region is the set of states for which the likelihood function is larger than some threshold
Here Matthias wants to give a new proof that was custom-made for QIP! It uses likelihood ratio regions for general measurements in a new way that all three authors came up with together. We can credit QIP with the result because the program committee forced Matthias+Renato to merge their talk with Robin Blume-Kohout’s. But the two papers had different assumptions, different techniques and different results! After discussing how to combine their proofs for pedagogical reasons (there wasn’t time to present both, and it also wouldn’t be so illuminating), they realized that they could use Matthias + Renato’s assumptions (which are more general) and Robin’s method (which is simpler) to get a result that is (more or less) stronger than either previous result.
Sandu Popescu:
The smallest possible thermal machines and the foundations of thermodynamics
Are there quantum effects in biology?
Biological systems are open, driven systems far from equilibrium.
Sandu: “In fact, I hope it is a long time before I myself reach equilibrium.”
This talk is somewhat classical, but it does talk about the physics of information, at small scales.
He talks about very small refrigerators/heat engines. It turns out there is no (necessary) tradeoff between size and efficiency; one can get Carnot efficiency with a three-level (qutrit) refrigerator, which is simultaneously optimal for both size and efficiency.
It was a great talk, but your humble bloggers had mostly reached their ground state by this point in the conference… see the photo at the top of the post.
QIP 2012 Day 4
Possible location of QIP 2014??

Aleksandrs Belovs
Span Programs for Functions with Constant-Sized 1-certificates, based on 1105.4024
Consider the problem of finding whether or not a triangle exists in a graph with n vertices. Naively using Grover’s algorithm requires time 

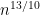

Before you roll your eyes and move to another tab, hear me out. The real improvement is in the technique, which is radically new, and has applications to many problems; not only triangle-finding.
The idea is to construct something called a learning graph. Each vertex is a subset of [n], and (directed) edges are weighted, and correspond to (sets of) queries. These are like randomized decision trees except they can have loops.
The complexity of the resulting algorithm (which we’ll describe below) is a little tricky to define. There is a “negative complexity” which is simply 
Algorithms in this model correspond to flows of intensity one. The vertex corresponding to the empty set is the root, and 1-certificates (i.e. proofs that x is indeed a yes instance) are the sinks. The cost is 

From a learning graph, there is a recipe to produce a span program, and in turn a quantum query algorithm, with the query complexity equal to the geometric mean of the negative and positive complexities of the learning graph.
As an example, consider the OR function. Here the learning graph is comprised entirely of a root and n leaves. Weight each edge by 1, so the negative complexity is n. If there are k solutions, then the resulting flows are 1/k on each edge, and so the positive complexity is 1/k. The algorithm’s complexity is 
Less trivial is element distinctness:
Are there two indices 
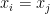
Again the algorithm achieves the optimal complexity, which is 
There are lots of new applications too, to improving the triangle runtime, but also getting a bunch of polynomial speedups for other problems that either are, or resemble, subgraph containment. For example, it improves some of the results from 1011.1443, and gets linear time algorithms to check whether a graph contains subgraphs from certain families, like lines, T-shaped things, and lines that go through stars.
Francois le Gall,
Improved output sensitive quantum algorithms for Boolean matrix multiplication
Boolean matrix multiplication means that the matrices are binary, + is replaced by OR, and * is replaced by AND. This arises in many cases, often related to graph theory, such as computing the transitive closure of a graph, triangle-detection, all-pairs shortest path, etc. Also it has application to recognizing context-free languages.
The naive algorithm is 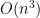


But suppose C has only one nonzero entry. Then we can do recursive Grover search and get time complexity 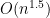
If it has 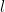

The parameter l represents the sparsity of matrix “output sensitive algorithms”.
In this work, the runtime is improved to 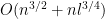
Richard Cleve Discrete simulations of continuous-time query algorithms that are efficient with respect to queries, gates and space, joint work with Dominic Berry and Sevag Gharibian.
After he was introduced, Richard sheepishly admitted, “The title isn’t really that efficient with its use of space.”
Normally the oracle for a quantum query algorithm defines the oracle query by flipping the phase of certain bits. In the continuous-time setting, we can get other phases. So, for example, a ”half-query” would give 



It is essential to be able to translate from the continuous-time model back to the discrete-time model for algorithmic applications. (cf. The work on NAND trees.) Is there a systematic way to do this translation? Yes, CGMSY-M `09 (improved by LMRSS `11) showed that the query complexity can be directly translated with the same number of queries. But these constructions are not gate efficient. Can we improve the gate complexity of the translation?
We have to be careful because the gate complexity will depend on the complexity of the driving Hamiltonian, so we have to carefully define a notion of approximately implementable Hamiltonian. If we have an epsilon-approximate implementation, and a driving Hamiltonian H, then the number of gates is at least 
Main results: We can translate from the continuous-time setting to the discrete-time setting by using:
 |
queries |
 |
gates |
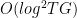 |
qubits of ancilla space |
Miklos Santha, Hidden Symmetry Subgroup Problems, joint work with Thomas Decker, Gábor Ivanyos and Pawel Wocjan
First let’s observe an interesting connection. In the dihedral group 

Can we more generally study subgroups which are hidden by symmetries? This generalizes and connects many problems in quantum algorithms, e.g. the hidden subgroup problem (HSP) over non-abelian groups, non-linear hidden structures and hidden polynomial problems among others, as the above example demonstrates.
Recall that the HSP is defined as follows. There is a function (for which you have an oracle) which is constant and distinct on the cosets of a subgroup of some group G. You want to obtain a generating set for the subgroup.
The hidden symmetry subgroup problem (HSSP): the input is a group G, a group action 




Rahul Jain and Ashwin Nayak:
A quantum information cost trade-off for the Augmented Index
Consider a twist (due to Yao ‘82) on the usual communication complexity problem. Alice has x, Bob has y, and they both want to compute f(x,y). But this time, they don’t want to leak (to the other party) more information than is already expressed by the answer, e.g. the millionaire problem.
Start with the usual example: equality testing. There is a O(log n) one-way protocol with 1/poly(n) error, and reveals only O(1) bits about one input.
Today’s talk is about:
Augmented index: Alice has 

They want to know whether 
(This has many connections to other works in theoretical computer science, not all of which are obviously communication-related. See paper for detail.)
Main result: For any quantum protocol which computes the augmented index with probability 
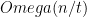
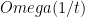
There is also an earlier classical result by the same authors: Alice reveals 
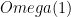

At this point, Ashwin, apparently reading the audience’s mind, puts up a slide that is not quite as pertinent as Josh Cadney’s opening question, but is still what we are all thinking:
“Why Augmented Index? Why privacy w.r.t. 0-inputs?”
Answer: Suppose we care about a streaming algorithm, which for quantum is relevant because we might only have O(1) qubits for the foreseeable future. There are exponential space improvements in this model, but let’s just say they don’t look like the sort of problems that Cisco was dying to implement on their routers. Augmented Index, by contrast, is much more natural. One semi-related version is Dyck(2), which is determining whether a sequence of (,),[,] is properly bracketed (this is a special case of recognizing context-free languages). Here we observe a big separation between one and two passes over the input (if the second pass goes in reverse order), and the lower bound on the (classical) one-pass complexity is based on (classical) lower bounds for the augmented index problem.
Having motivated the question, Ashwin is left with “-2 minutes” to finish his talk. Talk about a cliffhanger! Now he’s guaranteed to have the proof accepted to QIP 2013 (although he did give away the punchline by stating the theorem at the start of his talk). Moreover, the chair apparently has a sign for -2 minutes left, since he didn’t say anything, he just held up a sign. I guess staying on time is not a strong point in our community. 🙂
Ashwin is now ruining his cliffhanger, giving an intuitive and cute overview of the proof! He claims that this part of the talk is “in reverse.”
Sevag GharibianHardness of approximation for quantum problems, joint work with Julia Kempe
Finding the ground state energy of a local Hamiltonian is QMA-complete, and this is harder than NP, because, um, there’s quantum in there too, and well, it seems harder? Sev wants to say something more concrete here. We’ve given up on solving local Hamiltonian exactly in general, because we’ve already given up on solving NP on a quantum computer (mostly). But surely there are good approximation algorithms for these things. Right? Well, today, we’ll talk about hardness of approximation, thus casting complexity-theoretic cold water on seemingly less ambitious goals.
All we know about approximating the local Hamiltonian problem:
- PTAS on planar graphs
-
-approximation algorithm for dense graphs with k-local Hamiltonians.
This talk takes a step away from QMA, and considers instead the complexity class cq-
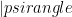
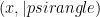
Their main result is to show that the following problem is complete for cq-
The quantum succinct set cover problem: Given a set of 5-local Hamiltonians acting on n qubits, and a parameter 

find the smallest subset 

The diagonal case was shown to be hard to approximate by Chris Umans in 1999.
For the technical details, there are lots of nice tools, and you’ll just have to look at the paper (when it comes out…).
Jérémie Roland,Quantum rejection sampling, joint work with Maris Ozols and Martin Roetteler
Let’s first review classical rejection sampling, which is a tool that you can use to sample from arbitrary probability distributions. It has numerous applications: Metropolis sampling, Monte Carlo algorithms, optimization algorithms (e.g. simulated annealing) and many others. In the quantum case, we wish to replace probabilities by amplitudes.
Consider two probability distributions P and S. Suppose we can sample from P repeatedly, but we wish to sample from S. Define ![Pr[{rm accept} k] = gamma s_k/p_k](https://s0.wp.com/latex.php?latex=Pr%5B%7Brm+accept%7D+k%5D+%3D+gamma+s_k%2Fp_k&bg=ffffff&fg=000&s=0&c=20201002)


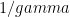
Now for the quantum case. We are given access to a black box which prepares a state 


Instead of computing a function, which is the normal thing that we use oracles for, we wish to generate a quantum state. There is an oracle, which is a unitary that hides the label 

Let’s define quantum state preparations:
We have a set of quantum states
set of oracles
Goal: generate 
What’s the minimum number of calls to the oracle to get the correct state (up to a coherent error with amplitude 
We introduce a coherent coin.
This rotated ancilla is like a classical coin, but now we have a superposition. If we measure the ancilla then we accept if we get one.
Using amplitude amplification, we can get a speedup over the naive accept probability.
We can also optimize over the rotation angle to get the optimum. This can be done efficiently since it’s an SDP. They can prove that this is an optimal algorithm. [photo 70]
Now for the applications. Linear systems of equations: the HHL algorithm basically just does phase estimation followed by quantum rejection sampling. [photo 71] The quantum Metropolis algorithm is a way to prepare a Gibbs state of H at inverse temperature beta.
Direct mapping of Metropolis MRRTT algorithm OK for diagonal Hamiltonians, but if Hamiltonian is not diagonal we want to avoid the work of diagonalizing it.
One of the reasons that the Q. Metropolis algorithm was difficult was that the “reject” moves required that you go back to a state that you just measured. You can avoid having to deal with this difficulty if you use quantum rejection sampling. One can amplify the accepted moves and therefore avoid having to revert moves at all!
Boolean hidden shift. f(x+s) = f(x) find s in Z_2^n. If the function is a delta function, then you can basically only do Grover. You can do bent functions (those with flat Fourier spectrum) with only 1 query [Roetteler 10]. These are the extreme cases, but what happens when we interpolate between them? We can use quantum rejection sampling to analyze this problem.
Other applications: Amplify QMA witnesses [MW05, NWZ09], prepare ground states of PEPS parent Hamiltonians on a quantum computer [STV11]. [photo 76]

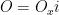
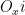

Rolando Somma, Spectral Gap Amplification, joint work with Sergio Boixo
Preparation of eigenstates is a central problem and fast quantum methods for computing expectation values of observables leads to speedups for many problems. Let’s begin by considering adiabatic state transformations. The run time is governed by the spectral gap of the interpolating Hamiltonian. The generic cost C(T) of a quantum algorithm that prepares the eigenstate depends on the inverse power of the spectral gap.
given H with eigenstate psi and gap Delta, can we construct an H with same eigenstate psi but a larger gap? (without cheating by multiplying by some constant?) We want to consider that the Hamiltonian is a sum of terms which are, say, local. We have a black box which on input k, s evolves according to 
They achieved a quadratic gap amplification for the following case: if H is frustration free, then the new gap is 
Question: What prevents you from iterating amplification process?
Ans. The new Hamiltonian isn’t FF, so you can only do the amplification once.
S. Flammia: Optimality of results?
Ans. There may be better constructions with respect to the scaling in L.
Rajat Mittal, Quantum query complexity for state conversion, joint work with Troy Lee, Ben Reichardt, Robert Spalek and Mario Szegedy
We live in a quantum world, so why are we always trying to solve classical tasks, like computing f(x), for x specified by an oracle? How about trying to prepare 

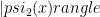

Previous work on adversary bounds gave a tight characterization of quantum query complexity for boolean functions. The present work extends the result to general functions, and indeed to state conversion.
Ok, what is this thing 
Without the 



w.r.t. 
e.g. 
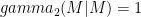
This gives some nice corollaries, e.g. that function composition does what you’d expect to query complexity.


Fernando Brandao, Random quantum circuits are unitary polynomial designs, joint work with Aram Harrow and Michal Horodecki
Previously blogged here.
Questions:
Patrick Hayden: To fool a circuit takes more time than the circuit does. Can you introduce some kind of restriction to make it go in a more favorable direction?
Aram: We could try to fool quantum Turing machines, but I don’t think our techniques say much that’d be helpful there.
Renato: Could you replace a random circuit by a random Hamiltonian?
Ans. Interesting question. Hayden et al do something like that. More interesting is to…
BUSINESS MEETING
The headline stat: 42 papers were accepted out of 198 submitted, meaning a 21% acceptance rate. (Louis also said the “real” rate was 29%.)
There were 485 reviews, of which 104 are from 72 external reviewers.
There were 198 = 144 (early) + 54 (late) poster submissions.
Of the 42 talks, there were 4 plenary, 9 long, 27 regular and 2 merged.
The budget breakdown is: rental+technical 55k, food+drinks 90k, personnel 30k, student support 10k for a of total 185k.
There were 259 participants of which 113 students.
Thus conference fees were 105k and there was 85k from sponsors. This leaves a surplus of 5k, presumably to cover damages during the rump session.
For the locals, the conference booklet explains how to get to the rump session. You take the metro, and as Louis said, “you will visit a lot of stations.” Note that this post will go online after the rump session.
Also, where is QIP 2013???
BEIJING! (specifically, Tsinghua University)
Local organizers are: Andy Yao (general chair), Amy Wang (organizing chair), Giulio Chiribella, Luming Duan, Kihwan Kim, Jian Li, Yaoyun Shi, Shengyu Zhang.
There is a new CQI at Tsinghua. You can guess what it stands for. Note that few permutations of those three letters remain.
Tentative dates are: Jan 21-25 or Jan 28-Feb 1, 2013.
A truly open question is: where will QIP 2014 be?
Two tentative proposals on the table are IBM Yorktown Heights and Barcelona.
But volunteers are still welcome! If you want the experience of hosting QIP, send an email to Louis Salvail soon.
Possible locations include a science museum, a university campus and… La Pedrera? Seriously? (See picture at the top of the post.)
Then there was general discussion about QIP.
Suggestions include
- not posting the long versions (at least without the authors confirming)
- Renaming QIP Workshop -> QIP Conference.
- Getting rid of the 3-page submissions? Here was the heated discussion. There always has to be a heated discussion about something.
- Dec vs Jan? The audience seemed to overwhelmingly prefer January (among those who cared). And yet here they are, all here in December!
QIP 2012 Day 3
PSPACE is a black hole gobbling up the other complexity classes.
And you thought the LHC was dangerous!
Troy Lee and Jérémie Roland:
A strong direct product theorem for quantum query complexity
Suppose you want to solve k independent instances of a problem with k-fold as many resources. For example, say you want to juggle 4 balls with two hands vs 2 balls with one hand.
A Strong Direct Product Theorem (SDPT) says (roughly) the following:
If we require r resources to solve one instance of a problem with success probability p, then using fewer than kr resources to solve k instances cannot succeed with probability greater than pk.
Intuitively, it ought to hold in many situations, but has been proven to hold only in a few. Some applications of SDPT:
- Making a hard function really hard, e.g. Yao’s XOR lemma
- Amplify soundness of a protocol, e.g. Raz
Here they study Quantum Query Complexity, which uses a black box oracle that can be queried in superposition, as a proxy for quantum time complexity. It behaves so well that it scarcely deserves to be called a computational model.
The big picture is that they use adversary methods and the state generation formalism due to Ambainis. The method defines a type of potential function and then bounds the rate of change from one query to the next. In the additive setting, they bound the difference, and in the multiplicative setting, they bound the ratio. The state generation method has the advantage that it allows the separation of lower bounds into two parts: the bound on the zero-error state generation and the minimization of this bound over the valid final Gram matrices of a successful protocol.
It is known that the multiplicative adversary method characterizes bounded-error quantum query complexity since the multiplicative adversary is at least as large as the additive one. One of the achievements of this paper is that they show that the multiplicative adversary method still works when the convergence ratio is strictly bounded away from one. This immediately implies a SDPT by the results of Spalek `08, but they reprove the SDPT from scratch so that they can get a better optimization of the parameters.
Conclusion and open problems: For Boolean functions, they show an XOR lemma. Does SDPT hold for all state generation problems? Is the multiplicative adversary method also tight in the case of large error?
André Chailloux and Or Sattath:
The Complexity of the Separable Hamiltonian Problem
First recall that QMA is the quantum analog of NP: it’s the set of problems which can be verified efficiently on a quantum computer when given a quantum proof (i.e. a quantum state for a witness). For QMA wth 2 provers, denoted QMA(2), there are two unentangled states which are given as proofs. It’s similar to interrogation of suspects: Author can play the two Merlins against each other and it is probably a much stronger class. (Each Merlin still sends poly(n) qubits, so QMA(2) is at least as strong as QMA, but is probably stronger.) Pure n-representability is known to be in QMA(2) but not known to be in QMA. It’s known that QMA(k) = QMA(2) for all k>2. We know only that QMA(2) 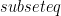
The main result of this paper is to find a complete problem for QMA(2). The separable local Hamiltonian problem is actually in QMA, but the separable sparse Hamiltonian problem is QMA(2) complete.
The problem: given a Hamiltonian 
Separable Local Hamiltonian: Given a local Hamiltonian H find a separable (say across an n by n qubit cut) 
This sure doesn’t look like it’s in QMA!
If the prover sends
Instead, the prover sends
Separable Sparse Hamiltonian: A totally different story! Now it’s QMA(2) complete. (The first known such problem.) Immediately we see that the qubit structure doesn’t exist, so we can’t rely on the strategy of looking at marginals. Clearly the problem is in QMA(2). To show completeness, we adapt Kitaev’s Hamiltonian for encoding a circuit (his so-called clock construction.) One challenge is that if the QMA(2) verifier makes an entangled measurement, then the history state will be entangled, which is not of the form we want. We want to simulate a computation in which the input is entangled, but we don’t care about the later steps; however, we are given the ability to minimize the energy of the sparse Hamiltonian for separable states, period.
The trick is that 1001.0017 shows that QMA(2) = QMA(2)-SEP, which is defined to be the class where the verifier is restricted to making separable (i.e. non-entangling measurements, at least for the yes outcome). This measurement requires a controlled-SWAP on the two proofs, which interestingly, is sparse, but not local. You might think you can build this out of a bunch of small controlled-SWAPs, but this would produce entanglement at intermediate steps. SWAP has a complicated relationship with entanglement. It doesn’t entangle product states, but only if it’s applied to the entire state; applying it to subsystems can create entanglement.
Many of the same open questions remain, about the status of QMA vs QMA(2) (although there is evidence from the case of log-size proofs to suggest that they are different), and about whether pure N-representability is also QMA(2) complete.
Yaoyun Shi and Xiaodi Wu:
Epsilon-net method for optimizations over separable states
The QMA(2) session continues! Once upon a time, I (Aram) thought QMA(2) was the kind of thing that complexity theorists make up to have more things to talk about, but I’ve since made a total U-turn. The problem, especially it’s log-size-witness variant, is equivalent to a ridiculously large number of problems, like separability testing, mean-field Hamiltonians, computing minimum output Rényi entropies of channels, finding the largest singular value of tensors, estimating the 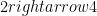
This talk changes this, with a pair of elementary approximation algorithms, one of which matches the performance of a weaker variant of 1010.1750 (details below).
To understand the basic problem, we don’t need to think about provers or circuits. The problem is as follows: Given a Hermitian matrix H on 
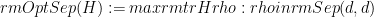
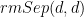
It is known that performing this optimization up to 1/poly(d) accuracy is NP-hard. (This result is originally due to Gurvits, although that’s not so widely known, since most people only noticed the part of his paper which talks about the hardness of testing membership in 
This talk gives two algorithms for approximating OptSep.
One works well when H is nearly product; in particular, when H can be decomposed as 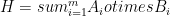

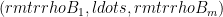

The second algorithm does eigenspace enumeration directly on H, and achieves additive error 
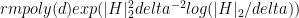
Abel Molina and John Watrous:
Hedging bets with correlated quantum strategies
Alice and Bob are at it again, playing a nonlocal game. Here is the framework: Alice prepares a question and sends it to Bob, Bob responds by sending an answer to Alice. Based on Bob’s answer, as well as whatever memory she has of her own question, Alice decides whether Bob has passed or failed a test.
Alice’s actions are specified by a density operator and a two outcome POVM. We assume that Bob knows a complete description of Alice. Then the games that they consider here can be formulated as a semidefinite program to determine Bob’s optimal success probability for passing the test.
Let’s consider parallel repetition: Alice performs two tests independently, but Bob can correlate his strategy in an arbitrary way. Suppose that Bob’s optimal probability to pass a single instantiation of a given test is p, and Alice independently runs the test twice. There are several natural questions: What is the optimal probability for Bob to pass both or at least one test? To pass k out of n independent tests? If Bob uses an independent strategy, you can just calculate the success probability of that. Can he do better by correlating his strategies?
If Alice’s test is classical, then Bob gains no advantage. In the quantum setting, Bob’s optimal probability to pass both tests is again p2, so he gains no advantage by correlating the tests. Both facts can be proven using SDP duality.
It would be natural to conjecture that it is also optimal for Bob to play independently if he only cares about passing at least one test. But this turns out to be false. They have a simple counterexample to this natural conjecture, and they compute Bob’s optimal strategy for a simple nonlocal game. The strategy is a form of hedging.
This work is in a different setting than other results with non-classical correlations of measurement outcomes. It might give insight into possible attacks in cryptography, where breaking the system only once is all you need: you don’t try independent attacks, instead you entangle a joint attack! It also gives reduced errors in quantum interactive proof protocols. So far, they have proved some partial results along these lines.
Comment by Richard Cleve: There is a classical strategy for hedging in the CHSH game which can perfectly win 1 out of 2 parallel games.
Jop Briet and Thomas Vidick:
Explicit lower and upper bounds on the entangled value of multiplayer XOR games
Bell’s theorem says that the set of correlations ![P[ab|xy]](https://s0.wp.com/latex.php?latex=P%5Bab%7Cxy%5D&bg=ffffff&fg=000&s=0&c=20201002)
![P[aoplus b | xy]](https://s0.wp.com/latex.php?latex=P%5Baoplus+b+%7C+xy%5D&bg=ffffff&fg=000&s=0&c=20201002)
For bipartite entanglement, we understand the situation pretty well now, but what about multipartite? (Another motivation is that quantifying multipartite entanglement is tough because it’s not clear what the goals are: this gives a nice clear way of keeping score.)
For a desired bias ratio R (meaning the entangled value is R times the unentangled value).
upper bound ( game) game)
| lower bound (Best possible) | |
| min questions | 
|  . .
|
| min local dimensions | 
| |
Here’s the outline of the proof.
- For any matrix (of appropriate size) we construct a 3-player XOR game.
- Relate R to spectral properties of matrix.
- Existence of a good matrix that gives a large separation
And the details.
1. Given R, choose n such that 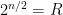
Give each player n qubits.
The game is to choose Paulis P,Q,R with probability 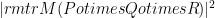
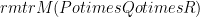
2. The entangled bias is at least the largest eigenvalue of 
The classical bias is the 2-2-2 norm, = 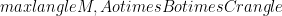

3. Choose
Some open questions: They leave open a gap of size R2 in the number of questions needed for an R-sized bias ratio. It would be nice to get a tight analysis. Another open question is to derandomize their construction.
Gus Gutoski and Xiaodi Wu:
Parallel approximation of min-max problems
with applications to classical and quantum zero-sum games
Everyone knows that QIP=PSPACE. But did you also know that SQG=QRG(2)=PSPACE? (Short quantum games, and two-turn quantum refereed games, of course.) All of these follow from using the multiplicative weights update method to solve large SDPs in parallel. (Here is a review of the multiplicative weights update method that doesn’t discuss quantum applications, and here is a review that does).
This work concerns 2-turn quantum refereed games. Some motivation comes from complexity theory. We can consider interactive proof systems with two competing provers, one trying to prove Yes and the other trying to prove No.
The key result is that SQG is contained in PSPACE thus unifying and simplifying previous results about various games and interactive proofs being equivalent to PSPACE.
Additionally, they showed that public coin RG is not equal to RG unless PSPACE = EXP. Thus, the case of two competing provers is different from the case of a single untrusted prover (the usual IP situation) in which the messages to the prover can be replaced by public coins.
The key technical result is a way to parallelize an SDP related to whether certain quantum states exist. SDPs in general cannot be parallelized unless NC=P, but this result is possible because it deals with normalized quantum states going through trace-preserving quantum channels, and so the multiplicative weights update method (MWUM) can give a good approximation. Indeed MWUM has previously been used to quickly find solutions to classical zero-sum games (and convex programs in general), so it is natural to examine it for quantum zero-sum games. And even though there may be many rounds of interactions, these can be modeled by a series of linear and semidefinite constraints, applied to the density matrices appearing at various intermediate steps. This “transcript representation” was originally invented by Kitaev (whose ghostly presence looms large over this entire conference) in his work on coin flipping.
They also discussed penalization and rounding theorems and space efficiency.
The best part was a nice artistic depiction of PSPACE as a black hole gobbling up the other complexity classes, as shown at the top of the page!