This Thanksgiving, even if we can’t all be fortunate enough to be presenting a talk at QIP, we can be thankful for being part of a vibrant research community with so many different lines of work going on. The QIP 2014 accepted talks are now posted with 36 out of 222 accepted. While many of the hot topics of yesteryear (hidden subgroup problem, capacity of the depolarizing channel) have fallen by the wayside, there is still good work happening in the old core topics (algorithms, information theory, complexity, coding, Bell inequalities) and in topics that have moved into the mainstream (untrusted devices, topological order, Hamiltonian complexity).
Here is a list of talks, loosely categorized by topic (inspired by Thomas’s list from last year). I’m pretty sad about missing my first QIP since I joined the field, because its unusually late timing overlaps the first week of the semester at MIT. But in advance of the talks, I’ll write a few words (in italics) about what I would be excited about hearing if I were there.
Quantum Shannon Theory
There are a lot of new entropies! Some of these may be useful – at first for tackling strong converses, but eventually maybe for other applications as well. Others may, well, just contribute to the entropy of the universe. The bounds on entanglement rate of Hamiltonians are exciting, and looking at them, I wonder why it took so long for us to find them.
1a. A new quantum generalization of the Rényi divergence with applications to the strong converse in quantum channel coding
Frédéric Dupuis, Serge Fehr, Martin Müller-Lennert, Oleg Szehr, Marco Tomamichel, Mark Wilde, Andreas Winter and Dong Yang. 1306.3142 1306.1586
merged with
1b. Quantum hypothesis testing and the operational interpretation of the quantum Renyi divergences
Milan Mosonyi and Tomohiro Ogawa. 1309.3228
25. Zero-error source-channel coding with entanglement
Jop Briet, Harry Buhrman, Monique Laurent, Teresa Piovesan and Giannicola Scarpa. 1308.4283
28. Bound entangled states with secret key and their classical counterpart
Maris Ozols, Graeme Smith and John A. Smolin. 1305.0848
It’s funny how bound key is a topic for quant-ph, even though it is something that is in principle purely a classical question. I think this probably is because of Charlie’s influence. (Note that this particular paper is mostly quantum.)
3a. Entanglement rates and area laws
Michaël Mariën, Karel Van Acoleyen and Frank Verstraete. 1304.5931 (This one could also be put in the condensed-matter category.)
merged with
3b. Quantum skew divergence
Koenraad Audenaert. 1304.5935
22. Quantum subdivision capacities and continuous-time quantum coding
Alexander Müller-Hermes, David Reeb and Michael Wolf. 1310.2856
Quantum Algorithms
This first paper is something I tried (unsuccessfully, needless to say) to disprove for a long time. I still think that this paper contains yet-undigested clues about the difficulties of non-FT simulations.
2a. Exponential improvement in precision for Hamiltonian-evolution simulation
Dominic Berry, Richard Cleve and Rolando Somma. 1308.5424
merged with
2b. Quantum simulation of sparse Hamiltonians and continuous queries with optimal error dependence
Andrew Childs and Robin Kothari.
update: The papers appear now to be merged. The joint (five-author) paper is 1312.1414.
35. Nested quantum walk
Andrew Childs, Stacey Jeffery, Robin Kothari and Frederic Magniez.
(not sure about arxiv # – maybe this is a generalization of 1302.7316?)
Quantum games: from Bell inequalities to Tsirelson inequalities
It is interesting how the first generation of quantum information results is about showing the power of entanglement, and now we are all trying to limit the power of entanglement. These papers are, in a sense, about toy problems. But I think the math of Tsirelson-type inequalities is going to be important in the future. For example, the monogamy bounds that I’ve recently become obsessed with can be seen as upper bounds on the entangled value of symmetrized games.
4a. Binary constraint system games and locally commutative reductions
Zhengfeng Ji. 1310.3794
merged with
4b. Characterization of binary constraint system games
Richard Cleve and Rajat Mittal. 1209.2729
20. A parallel repetition theorem for entangled projection games
Irit Dinur, David Steurer and Thomas Vidick. 1310.4113
33. Parallel repetition of entangled games with exponential decay via the superposed information cost
André Chailloux and Giannicola Scarpa. 1310.7787
Untrusted randomness generation
Somehow self-testing has exploded! There is a lot of information theory here, but the convex geometry of conditional probability distributions also is relevant, and it will be interesting to see more connections here in the future.
5a. Self-testing quantum dice certified by an uncertainty principle
Carl Miller and Yaoyun Shi.
merged with
5b. Robust device-independent randomness amplification from any min-entropy source
Kai-Min Chung, Yaoyun Shi and Xiaodi Wu.
19. Infinite randomness expansion and amplification with a constant number of devices
Matthew Coudron and Henry Yuen. 1310.6755
29. Robust device-independent randomness amplification with few devices
Fernando Brandao, Ravishankar Ramanathan, Andrzej Grudka, Karol Horodecki, Michal Horodecki and Pawel Horodecki. 1310.4544
The fuzzy area between quantum complexity theory, quantum algorithms and classical simulation of quantum systems. (But not Hamiltonian complexity.)
I had a bit of trouble categorizing these, and also in deciding how surprising I should find each of the results. I am also somewhat embarrassed about still not really knowing exactly what a quantum double is.
6. Quantum interactive proofs and the complexity of entanglement detection
Kevin Milner, Gus Gutoski, Patrick Hayden and Mark Wilde. 1308.5788
7. Quantum Fourier transforms and the complexity of link invariants for quantum doubles of finite groups
Hari Krovi and Alexander Russell. 1210.1550
16. Purifications of multipartite states: limitations and constructive methods
Gemma De Las Cuevas, Norbert Schuch, David Pérez-García and J. Ignacio Cirac.
Hamiltonian complexity started as a branch of quantum complexity theory but by now has mostly devoured its host
A lot of exciting results. The poly-time algorithm for 1D Hamiltonians appears not quite ready for practice yet, but I think it is close. The Cubitt-Montanaro classification theorem brings new focus to transverse-field Ising, and to the weird world of stoquastic Hamiltonians (along which lines I think the strengths of stoquastic adiabatic evolution deserve more attention). The other papers each do more or less what we expect, but introduce a lot of technical tools that will likely see more use in the coming years.
13. A polynomial-time algorithm for the ground state of 1D gapped local Hamiltonians
Zeph Landau, Umesh Vazirani and Thomas Vidick. 1307.5143
15. Classification of the complexity of local Hamiltonian problems
Toby Cubitt and Ashley Montanaro. 1311.3161
30. Undecidability of the spectral gap
Toby Cubitt, David Pérez-García and Michael Wolf.
23. The Bose-Hubbard model is QMA-complete
Andrew M. Childs, David Gosset and Zak Webb. 1311.3297
24. Quantum 3-SAT is QMA1-complete
David Gosset and Daniel Nagaj. 1302.0290
26. Quantum locally testable codes
Dorit Aharonov and Lior Eldar. (also QECC) 1310.5664
Codes with spatially local generators aka topological order aka quantum Kitaev theory
If a theorist is going to make some awesome contribution to building a quantum computer, it will probably be via this category. Yoshida’s paper is very exciting, although I think the big breakthroughs here were in Haah’s still underappreciated masterpiece. Kim’s work gives operational meaning to the topological entanglement entropy, a quantity I had always viewed with perhaps undeserved skepticism. It too was partially anticipated by an earlier paper, by Osborne.
8. Classical and quantum fractal code
Beni Yoshida. I think this title is a QIP-friendly rebranding of 1302.6248
21. Long-range entanglement is necessary for a topological storage of information
Isaac Kim. 1304.3925
Bit commitment is still impossible (sorry Horace Yuen) but information-theoretic two-party crypto is alive and well
The math in this area is getting nicer, and the protocols more realistic. The most unrealistic thing about two-party crypto is probably the idea that it would ever be used, when people either don’t care about security or don’t even trust NIST not to be a tool of the NSA.
10. Entanglement sampling and applications
Frédéric Dupuis, Omar Fawzi and Stephanie Wehner. 1305.1316
36. Single-shot security for one-time memories in the isolated qubits model
Yi-Kai Liu. 1304.5007
Communication complexity
It is interesting how quantum and classical techniques are not so far apart for many of these problems, in part because classical TCS is approaching so many problem using norms, SDPs, Banach spaces, random matrices, etc.
12. Efficient quantum protocols for XOR functions
Shengyu Zhang. 1307.6738
9. Noisy Interactive quantum communication
Gilles Brassard, Ashwin Nayak, Alain Tapp, Dave Touchette and Falk Unger. 1309.2643 (also info th / coding)
Foundations
I hate to be a Philistine, but I wonder what disaster would befall us if there WERE a psi-epistemic model that worked. Apart from being able to prove false statements. Maybe a commenter can help?
14. No psi-epistemic model can explain the indistinguishability of quantum states
Eric Cavalcanti, Jonathan Barrett, Raymond Lal and Owen Maroney. 1310.8302
??? but it’s from THE RAT
update: A source on the PC says that this is an intriguing mixture of foundations and Bell inequalities, again in the “Tsirelson regime” of exploring the boundary between quantum and non-signaling.
17. Almost quantum
Miguel Navascues, Yelena Guryanova, Matty Hoban and Antonio Acín.
FTQC/QECC/papers Kalai should read 🙂
I love the part where Daniel promises not to cheat. Even though I am not actively researching in this area, I think the race between surface codes and concatenated codes is pretty exciting.
18. What is the overhead required for fault-tolerant quantum computation?
Daniel Gottesman. 1310.2984
27. Universal fault-tolerant quantum computation with only transversal gates and error correction
Adam Paetznick and Ben Reichardt. 1304.3709
Once we equilibrate, we will still spend a fraction of our time discussing thermodynamics and quantum Markov chains
I love just how diverse and deep this category is. There are many specific questions that would be great to know about, and the fact that big general questions are still being solved is a sign of how far we still have to go. I enjoyed seeing the Brown-Fawzi paper solve problems that stumped me in my earlier work on the subject, and I was also impressed by the Cubitt et al paper being able to make a new and basic statement about classical Markov chains. The other two made me happy through their “the more entropies the better” approach to the world.
31. An improved Landauer Principle with finite-size corrections and applications to statistical physics
David Reeb and Michael M. Wolf. 1306.4352
32. The second laws of quantum thermodynamics
Fernando Brandao, Michal Horodecki, Jonathan Oppenheim, Nelly Ng and Stephanie Wehner. 1305.5278
34. Decoupling with random quantum circuits
Winton Brown and Omar Fawzi. 1307.0632
11. Stability of local quantum dissipative systems
Toby Cubitt, Angelo Lucia, Spyridon Michalakis and David Pérez-García. 1303.4744

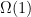

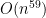 , also known as “polynomial time” or “efficient”.
, also known as “polynomial time” or “efficient”.
![\omega(G) = \sup_{\textrm{Merlins}} \textrm{Pr}[\text{Arthur accepts}]](https://s0.wp.com/latex.php?latex=%5Comega%28G%29+%3D+%5Csup_%7B%5Ctextrm%7BMerlins%7D%7D+%5Ctextrm%7BPr%7D%5B%5Ctext%7BArthur+accepts%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) . We need to ensure that this scheme is both sound and complete. A stronger version known as the PCP theorem has the following interesting property. Arthur can do some pre-processing and then just check a constant number of clauses to get a high probability of soundness.
. We need to ensure that this scheme is both sound and complete. A stronger version known as the PCP theorem has the following interesting property. Arthur can do some pre-processing and then just check a constant number of clauses to get a high probability of soundness. qubits with a promise that the ground state energy is either less than
qubits with a promise that the ground state energy is either less than  or greater than
or greater than  , with
, with 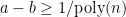 (the “promise gap”), and one must decide which is the case.
(the “promise gap”), and one must decide which is the case.![\omega^*(G) = \sup_{\textrm{Merlins}} \textrm{Pr}[\text{Arthur accepts}]](https://s0.wp.com/latex.php?latex=%5Comega%5E%2A%28G%29+%3D+%5Csup_%7B%5Ctextrm%7BMerlins%7D%7D+%5Ctextrm%7BPr%7D%5B%5Ctext%7BArthur+accepts%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) . The star denotes this additional quantum entanglement shared by the Merlins.
. The star denotes this additional quantum entanglement shared by the Merlins.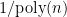 factor. Consider the ground state of the Hamiltonian encoded in the
factor. Consider the ground state of the Hamiltonian encoded in the 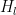 on qubits
on qubits  and either:
and either: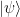 and to respond to a request for qubit
and to respond to a request for qubit  by applying a unitary
by applying a unitary 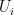 , or to a request for
, or to a request for  . We would like to argue that any such strategy can be turned into a method for extracting all
. We would like to argue that any such strategy can be turned into a method for extracting all  ), and then replace those qubits with halves of EPR pairs and then each prover applies
), and then replace those qubits with halves of EPR pairs and then each prover applies 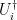 . Actually, the other halves of the EPR pairs are never used so even a maximally mixed state would work. The point is just to put something there, effectively performing a logical SWAP.
. Actually, the other halves of the EPR pairs are never used so even a maximally mixed state would work. The point is just to put something there, effectively performing a logical SWAP. are QMA hard. The result is a first step in this direction by solving the case of a
are QMA hard. The result is a first step in this direction by solving the case of a 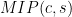 refers to the class of problems with a multi-prover interactive proof with completeness c and soundness s. In this language the PCP theorem implies that
refers to the class of problems with a multi-prover interactive proof with completeness c and soundness s. In this language the PCP theorem implies that 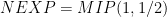 .
. in an earlier breakthrough. This work shows now that
in an earlier breakthrough. This work shows now that  is contained in
is contained in 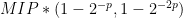 , proving for the first time that entanglement increases the power of quantum proof systems. Here “proving” is in the usual complexity-theory sense, where we have to make some plausible assumption: in this case, that
, proving for the first time that entanglement increases the power of quantum proof systems. Here “proving” is in the usual complexity-theory sense, where we have to make some plausible assumption: in this case, that  .
.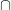 postBPP, which is unlikely to equal BQP.
postBPP, which is unlikely to equal BQP.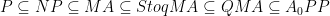
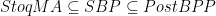

 and SBP are approximate counting classes.)
and SBP are approximate counting classes.) is restricted to be real with respect to the computational basis for all times. We also have to use a restricted gate set that is CSS-preserving, and purely Clifford. This also affects the state preparations and measurements that are allowed, but let’s skip the details.
is restricted to be real with respect to the computational basis for all times. We also have to use a restricted gate set that is CSS-preserving, and purely Clifford. This also affects the state preparations and measurements that are allowed, but let’s skip the details. Hudson’s theorem: A pure n-rebit state has a non-negative Wigner function if and only if it is a CSS stabilizer state.
Hudson’s theorem: A pure n-rebit state has a non-negative Wigner function if and only if it is a CSS stabilizer state.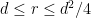 .
.
 and the same guarantees on the spectral gap, do not match any of the condensed matter theorists’ explanations. They only require spins of dimension 5, so they are much closer to a natural model.
and the same guarantees on the spectral gap, do not match any of the condensed matter theorists’ explanations. They only require spins of dimension 5, so they are much closer to a natural model.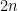 .
. is a Gaussian channel, then
is a Gaussian channel, then for all
for all 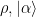 .
. entropy for
entropy for  . There is also a phase space majorization result.
. There is also a phase space majorization result.
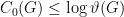 (sometimes known to be strict)
(sometimes known to be strict)
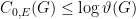
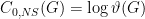
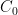 ), entanglement (
), entanglement (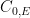 ) or no-signalling correlations (
) or no-signalling correlations (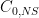 ). On the RHS we have the Lovasz theta number (see below) which can be calculated efficiently using semidefinite programming.
). On the RHS we have the Lovasz theta number (see below) which can be calculated efficiently using semidefinite programming. .)
.)
 constraint with
constraint with 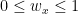 , then observing that the upper bound is superlative:
, then observing that the upper bound is superlative: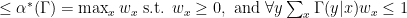 .
.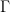 consistent with
consistent with  gives
gives  .
. is multiplicative and satisfies
is multiplicative and satisfies 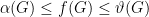 , then we must have
, then we must have 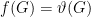 ! This is unpublished still, but follows from the beautiful formula [personal communication from Winter, via my memory, so hopefully not too wrong]:
! This is unpublished still, but follows from the beautiful formula [personal communication from Winter, via my memory, so hopefully not too wrong]: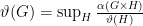 .
.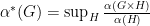 .
. and output
and output 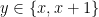 . Then
. Then  ,
, 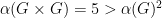 ,
, 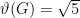 (thus giving a tight upper bound on the capacity) and
(thus giving a tight upper bound on the capacity) and 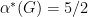 .
. and
and 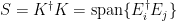 .
.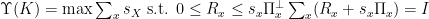 . This is
. This is .
.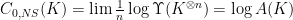 .
. .
. ,
, 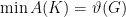 , which is the first information-theoretic application of the Lovasz theta function.
, which is the first information-theoretic application of the Lovasz theta function.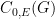 and
and  ?
?
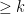 bits of min-entropy correspond to probability distributions (i.e.
bits of min-entropy correspond to probability distributions (i.e. 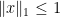 ) with all entries
) with all entries 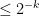 , (i.e.
, (i.e.  ). The intersection of these two constraints defines a centrally symmetric convex set (if we subtract off the uniform distribution, I suppose), which can then define a norm. One other example of such a hybrid norm is the family of
). The intersection of these two constraints defines a centrally symmetric convex set (if we subtract off the uniform distribution, I suppose), which can then define a norm. One other example of such a hybrid norm is the family of  norm and the denominator in this funny hybrid norm.
norm and the denominator in this funny hybrid norm.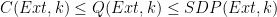 .
. -design is that it is a discrete set of unitary operators that exactly reproduce the first
-design is that it is a discrete set of unitary operators that exactly reproduce the first 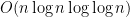 gates, but it assumes an extension of the Riemann hypothesis. Without this hypothesis, they also have a non-Clifford construction with the same complexity, and a Clifford-only scheme with complexity
gates, but it assumes an extension of the Riemann hypothesis. Without this hypothesis, they also have a non-Clifford construction with the same complexity, and a Clifford-only scheme with complexity  . Sampling uniformly from the Clifford group has gate complexity
. Sampling uniformly from the Clifford group has gate complexity  , so this is an improvement.
, so this is an improvement.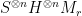 , where the matrix
, where the matrix  has a decomposition with low complexity that is the main technical contribution of the authors. By using the result that Pauli mixing by conjugation implies unitary 2-design, one only needs to consider certain forms of the matrix
has a decomposition with low complexity that is the main technical contribution of the authors. By using the result that Pauli mixing by conjugation implies unitary 2-design, one only needs to consider certain forms of the matrix ![Y = \text{tr} [\rho_+^{1+\epsilon} + \rho_-^{1-\epsilon}] / \text{tr}[\rho^{1+\epsilon}]](https://s0.wp.com/latex.php?latex=Y+%3D+%5Ctext%7Btr%7D+%5B%5Crho_%2B%5E%7B1%2B%5Cepsilon%7D+%2B+%5Crho_-%5E%7B1-%5Cepsilon%7D%5D+%2F+%5Ctext%7Btr%7D%5B%5Crho%5E%7B1%2B%5Cepsilon%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) and
and ![X = \text{tr} [\rho_0^{1+\epsilon}] / \text{tr} [\rho^{1+\epsilon}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Ctext%7Btr%7D+%5B%5Crho_0%5E%7B1%2B%5Cepsilon%7D%5D+%2F+%5Ctext%7Btr%7D+%5B%5Crho%5E%7B1%2B%5Cepsilon%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) where
where 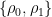 and
and 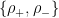 are the post-measurement states resulting from a pair of anticommuting measurements on
are the post-measurement states resulting from a pair of anticommuting measurements on 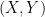 must fit into a particular region of the plane. (see eq (2.2) of their paper for a bit more detail.)
must fit into a particular region of the plane. (see eq (2.2) of their paper for a bit more detail.) norm” due to
norm” due to ![\mathbb{Z}[\sqrt{2}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Csqrt%7B2%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) define
define 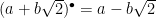 and the norm
and the norm 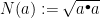 .
.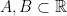 , find an element of
, find an element of 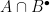 . Generically there will be
. Generically there will be  solutions, and these are easy to find when both
solutions, and these are easy to find when both 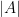 and
and  are large, corresponding to a fat rectangle (when
are large, corresponding to a fat rectangle (when ![\mathbb{Z}[2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B2%5D&bg=ffffff&fg=000&s=0&c=20201002) is viewed as a 2-d lattice). When we have a long thin rectangle we can convert it into this case by rescaling.
is viewed as a 2-d lattice). When we have a long thin rectangle we can convert it into this case by rescaling.![\mathbb{Z}[\omega]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Comega%5D&bg=ffffff&fg=000&s=0&c=20201002) for
for 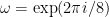 . This turns into a more complicated set intersection problem on a 2-d lattice whose details we omit. But just like the rescaling used for 1-d, now we use a more complicated set of shearing operators to transform the problem into one where the solutions are easier to find. But we need an extra property: the “uprightness” of the rectangles.
. This turns into a more complicated set intersection problem on a 2-d lattice whose details we omit. But just like the rescaling used for 1-d, now we use a more complicated set of shearing operators to transform the problem into one where the solutions are easier to find. But we need an extra property: the “uprightness” of the rectangles.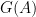 and
and 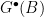 are both 1/6 upright. Moreover, it can be efficiently computed.
are both 1/6 upright. Moreover, it can be efficiently computed. a 2-by-2 unitary operator, then it is Clifford+T iff the matrix elements are all of the form
a 2-by-2 unitary operator, then it is Clifford+T iff the matrix elements are all of the form ![\frac{1}{2^{k/2}} \mathbb{Z}[\omega])](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%5E%7Bk%2F2%7D%7D+%5Cmathbb%7BZ%7D%5B%5Comega%5D%29&bg=ffffff&fg=000&s=0&c=20201002) where
where  . Moreover, if
. Moreover, if 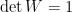 , then the T-count of the resulting operator is equal to
, then the T-count of the resulting operator is equal to 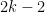 .
. plus a term of order
plus a term of order 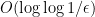 .
.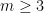 . In other words, any beamsplitter that mixes modes is universal for three or more modes. Another way to say this is that for any beamsplitter
. In other words, any beamsplitter that mixes modes is universal for three or more modes. Another way to say this is that for any beamsplitter  such that quantum state tomography and quantum state verification can be done efficiently. We would like to also have that if a state is in
such that quantum state tomography and quantum state verification can be done efficiently. We would like to also have that if a state is in 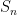 that has this verification property in time
that has this verification property in time  where
where  such that
such that .
. can be reconstructed from the marginals of a state
can be reconstructed from the marginals of a state 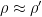 . The global state is completely determined by the local reduced density operators if the conditional quantum mutual information is zero.
. The global state is completely determined by the local reduced density operators if the conditional quantum mutual information is zero. and
and  then
then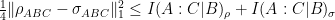
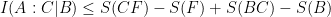
 .
. in 2-d), this bound is effective.
in 2-d), this bound is effective. has the same syndrome as
has the same syndrome as 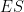 if
if 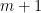 correctable regions, then you can only implement gates in level
correctable regions, then you can only implement gates in level  -dimensional topological codes can be split into
-dimensional topological codes can be split into  correctable regions, so we can only implement gates at level
correctable regions, so we can only implement gates at level  for some number
for some number  . If you have a
. If you have a  logic gate, then
logic gate, then 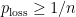 .
.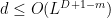 . This improves a bound of
. This improves a bound of 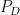 (as long as the code distance grows at least logarithmically in the system size).
(as long as the code distance grows at least logarithmically in the system size).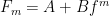 where
where  is a quantity closely related to the average quality of the gates in the sequence. Define
is a quantity closely related to the average quality of the gates in the sequence. Define  to be the average error rate. (Morally, this is equivalent to “1-f”, in the above model, but the actual formula is more complicated.) To understand the convergence of this protocol to an estimate, we need to understand the variance as a function of
to be the average error rate. (Morally, this is equivalent to “1-f”, in the above model, but the actual formula is more complicated.) To understand the convergence of this protocol to an estimate, we need to understand the variance as a function of  .
. to
to  . This provides a good guide on how to choose optimal lengths
. This provides a good guide on how to choose optimal lengths  dimensions or even worse. But we often have a mental models of them as basically like non-interacting spins. In some cases, the renormalization group and other arguments can partially justify this. One thing that’s true in the case of non-interacting spins is that the density of states is approximately Gaussian. The idea here is to show that this still holds when we replace “non-interacting spins” with something morally similar, such as exponentially decaying correlations, bounded-range interactions, etc.
dimensions or even worse. But we often have a mental models of them as basically like non-interacting spins. In some cases, the renormalization group and other arguments can partially justify this. One thing that’s true in the case of non-interacting spins is that the density of states is approximately Gaussian. The idea here is to show that this still holds when we replace “non-interacting spins” with something morally similar, such as exponentially decaying correlations, bounded-range interactions, etc. . These states are far apart in trace distance, but this paper shows that they look similar with respect to sufficiently local observables. If you think this sounds easy, well, then try to prove it yourself, and then once you give up, read this paper.
. These states are far apart in trace distance, but this paper shows that they look similar with respect to sufficiently local observables. If you think this sounds easy, well, then try to prove it yourself, and then once you give up, read this paper.![\dot\rho = -\mathcal{A}[\rho]](https://s0.wp.com/latex.php?latex=%5Cdot%5Crho+%3D+-%5Cmathcal%7BA%7D%5B%5Crho%5D&bg=ffffff&fg=000&s=0&c=20201002) for some linear superoperator
for some linear superoperator  , which we will assume to be Hermitian for convenience.
, which we will assume to be Hermitian for convenience.  , where
, where  and
and  on
on 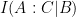 .
.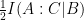 .
.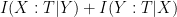 , where X,Y are the inputs for Alice and Bob respectively. In the quantum case we realize that the very idea of a transcript implicitly uses the principle that (classical) information can be freely copied, and so for quantum protocols we cannot use it. Instead Dave just sums the QCMI (quantum conditional mutual information) of each step of the protocol. This means
, where X,Y are the inputs for Alice and Bob respectively. In the quantum case we realize that the very idea of a transcript implicitly uses the principle that (classical) information can be freely copied, and so for quantum protocols we cannot use it. Instead Dave just sums the QCMI (quantum conditional mutual information) of each step of the protocol. This means 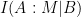 when Alice sends
when Alice sends  to Bob and
to Bob and 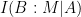 when Bob sends
when Bob sends  to Alice. Here
to Alice. Here 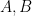 refer to the entire systems of Alice/Bob respectively. (Earlier work by Yao and Cleve-Buhrman approached this in other, less ideal, ways.)
refer to the entire systems of Alice/Bob respectively. (Earlier work by Yao and Cleve-Buhrman approached this in other, less ideal, ways.) (i.e. it is the minimum sum of QCMI’s over all protocols that compute the function up to error
(i.e. it is the minimum sum of QCMI’s over all protocols that compute the function up to error 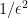 and an additive term that also scales with the number of rounds. Since QIC is also a lower bound for the above amortized version of complexity, this proves a direct sum theorem, meaning that computing
and an additive term that also scales with the number of rounds. Since QIC is also a lower bound for the above amortized version of complexity, this proves a direct sum theorem, meaning that computing  as much as one function evaluation. Here the weak amortized definition actually makes the result stronger, since we are proving lower bounds on the communication cost. In other words, the lower bound also applies to the case of low block-wise error.
as much as one function evaluation. Here the weak amortized definition actually makes the result stronger, since we are proving lower bounds on the communication cost. In other words, the lower bound also applies to the case of low block-wise error. has turned into a quagmire that has now lasted longer than the Vietnam War.
has turned into a quagmire that has now lasted longer than the Vietnam War.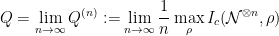 ,
,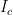 is the coherent information (see paper for def). In evaluating this formula, how large do we have to take n? e.g. could prove that we always have
is the coherent information (see paper for def). In evaluating this formula, how large do we have to take n? e.g. could prove that we always have 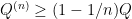 ? If this, or some formula like it, were true then we would get an explicit upper bound on the complexity of estimating capacity.
? If this, or some formula like it, were true then we would get an explicit upper bound on the complexity of estimating capacity. but
but 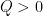 .
.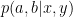 that have well-defined marginals
that have well-defined marginals  and
and  .) One way to think about it is as a relaxation of the set of “quantum” distributions, meaning the input-output distributions that are compatible with entangled states. The no-signalling polytope is defined by a polynomial number of linear constraints, and so is the sort of relaxation that is amenable to linear programming, whereas we don’t even know whether the quantum value of a game is computable. But is the no-signalling condition ever interesting in itself?
.) One way to think about it is as a relaxation of the set of “quantum” distributions, meaning the input-output distributions that are compatible with entangled states. The no-signalling polytope is defined by a polynomial number of linear constraints, and so is the sort of relaxation that is amenable to linear programming, whereas we don’t even know whether the quantum value of a game is computable. But is the no-signalling condition ever interesting in itself?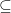 MIPns[poly provers]
MIPns[poly provers]  whose weights add up to a particular target. Indeed this algorithm has a query complexity for the unweighted case that is known to be impossible for the weighted version. A related point is that this shows the limitations of the otherwise versatile non-adaptive learning-graph method.
whose weights add up to a particular target. Indeed this algorithm has a query complexity for the unweighted case that is known to be impossible for the weighted version. A related point is that this shows the limitations of the otherwise versatile non-adaptive learning-graph method.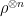 for
for 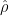 in a way that achieves
in a way that achieves  .
.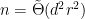 for single-copy two-outcome measurements of rank-
for single-copy two-outcome measurements of rank-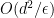 is possible using using the Local Asymptotic Normality results of Guta and Kahn [
is possible using using the Local Asymptotic Normality results of Guta and Kahn [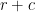 ? The symmetry of the problem (invariant under both permutations and rotations of the form
? The symmetry of the problem (invariant under both permutations and rotations of the form  ) means that we can WLOG consider “weak Schur sampling” meaning that we measure which
) means that we can WLOG consider “weak Schur sampling” meaning that we measure which 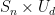 irrep our state lies in, and output some function of this result. This irrep is described by an integer partition which, when normalized, is a sort of mangled estimate of the spectrum. It remains only to analyze the accuracy of this estimator in various ways. In many of the interesting cases we can say something nontrivial even if
irrep our state lies in, and output some function of this result. This irrep is described by an integer partition which, when normalized, is a sort of mangled estimate of the spectrum. It remains only to analyze the accuracy of this estimator in various ways. In many of the interesting cases we can say something nontrivial even if  . This involves some delicate calculations using a lot of symmetric polynomials. Some of these first steps (including many of the canonical ones worked out much earlier by people like Werner) are in my paper
. This involves some delicate calculations using a lot of symmetric polynomials. Some of these first steps (including many of the canonical ones worked out much earlier by people like Werner) are in my paper 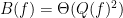 . There were several other interesting results in this talk, but we ran out of steam as it was the last talk before lunch.
. There were several other interesting results in this talk, but we ran out of steam as it was the last talk before lunch.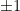 , we can factor composite numbers into
, we can factor composite numbers into 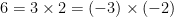 . Both of these are equally valid factorizations; they are equivalent modulo units. In more complicated settings where unique factorization fails, we have factorization into prime ideals, and the group of units can in general become infinite (though always discrete).
. Both of these are equally valid factorizations; they are equivalent modulo units. In more complicated settings where unique factorization fails, we have factorization into prime ideals, and the group of units can in general become infinite (though always discrete). .
.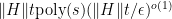 where
where  is the sparsity. I also remember believing that the known optimality thoerems for Trotter-Suzuki (sorry I can’t find the reference, but it involves decomposing
is the sparsity. I also remember believing that the known optimality thoerems for Trotter-Suzuki (sorry I can’t find the reference, but it involves decomposing 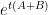 for the free Lie algebra generated by
for the free Lie algebra generated by  where
where  (where
(where 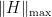 is
is 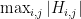 can be related to the earlier bounds via
can be related to the earlier bounds via 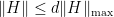 ).
). they cannot produce even a single bit with correlation
they cannot produce even a single bit with correlation 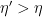 if they don’t communicate. This was famously proved by
if they don’t communicate. This was famously proved by  where
where 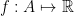 ,
, 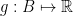 and each have variance 1. Properties:
and each have variance 1. Properties:
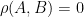 iff
iff 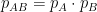


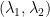 such that for any
such that for any 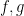 we have
we have![\mathbb{E}[f_A g_B] \leq \|f_A\|_{\frac{1}{\lambda_1}} \|g_B\|_{\frac{1}{\lambda_2}}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bf_A+g_B%5D+%5Cleq+%5C%7Cf_A%5C%7C_%7B%5Cfrac%7B1%7D%7B%5Clambda_1%7D%7D+%5C%7Cg_B%5C%7C_%7B%5Cfrac%7B1%7D%7B%5Clambda_2%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
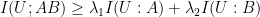
![[0,1]\times [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5Ctimes+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002) iff A,B are independent.
iff A,B are independent.
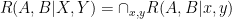 . The main theorem is then that rewiring never shrinks hypercontractivity ribbon. And as a result, PR box noise cannot be reduced.
. The main theorem is then that rewiring never shrinks hypercontractivity ribbon. And as a result, PR box noise cannot be reduced.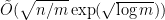 . Here “random” means something subtle. The text is uniformly random and the pattern is either uniformly random (in the “no” case) or is a random substring of the text (in the “yes” case). There is also a higher-dimensional generalization of the result.
. Here “random” means something subtle. The text is uniformly random and the pattern is either uniformly random (in the “no” case) or is a random substring of the text (in the “yes” case). There is also a higher-dimensional generalization of the result. , which is almost exactly when Ashley’s speedup becomes merely quadratic. So pattern matching is a total function whose hard distributions all look “partial” in some way, at least when quantum speedups are possible. This is somewhat vague, and it may be that some paper out there expresses the idea more clearly.
, which is almost exactly when Ashley’s speedup becomes merely quadratic. So pattern matching is a total function whose hard distributions all look “partial” in some way, at least when quantum speedups are possible. This is somewhat vague, and it may be that some paper out there expresses the idea more clearly.
{kind=link}