
(An earlier version of this post appeared in the latest newsletter of the American Physical Society’s special interest group on Quantum Information.)
One of the most grandly pessimistic ideas from the 19th century is that of “heat death” according to which a closed system, or one coupled to a single heat bath at thermal equilibrium, eventually inevitably settles into an uninteresting state devoid of life or macroscopic motion. Conversely, in an idea dating back to Darwin and Spencer, nonequilibrium boundary conditions are thought to have caused or allowed the biosphere to self-organize over geological time. Such godless creation, the bright flip side of the godless hell of heat death, nowadays seems to worry creationists more than Darwin’s initially more inflammatory idea that people are descended from apes. They have fought back, using superficially scientific arguments, in their masterful peanut butter video.

Much simpler kinds of complexity generation occur in toy models with well-defined dynamics, such as this one-dimensional reversible cellular automaton. Started from a simple initial condition at the left edge (periodic, but with a symmetry-breaking defect) it generates a deterministic wake-like history of growing size and complexity. (The automaton obeys a second order transition rule, with a site’s future differing from its past iff exactly two of its first and second neighbors in the current time slice, not counting the site itself, are black and the other two are white.)

Time →
But just what is it that increases when a self-organizing system organizes itself?
Such organized complexity is not a thermodynamic potential like entropy or free energy. To see this, consider transitions between a flask of sterile nutrient solution and the bacterial culture it would become if inoculated by a single seed bacterium. Without the seed bacterium, the transition from sterile nutrient to bacterial culture is allowed by the Second Law, but prohibited by a putative “slow growth law”, which prohibits organized complexity from increasing quickly, except with low probability.

The same example shows that organized complexity is not an extensive quantity like free energy. The free energy of a flask of sterile nutrient would be little altered by adding a single seed bacterium, but its organized complexity must have been greatly increased by this small change. The subsequent growth of many bacteria is accompanied by a macroscopic drop in free energy, but little change in organized complexity.
The relation between universal computer programs and their outputs has long been viewed as a formal analog of the relation between theory and phenomenology in science, with the various programs generating a particular output x being analogous to alternative explanations of the phenomenon x. This analogy draws its authority from the ability of universal computers to execute all formal deductive processes and their presumed ability to simulate all processes of physical causation.
In algorithmic information theory the Kolmogorov complexity, of a bit string x as defined as the size in bits of its minimal program x*, the smallest (and lexicographically first, in case of ties) program causing a standard universal computer U to produce exactly x as output and then halt.
x* = min{p: U(p)=x}
Because of the ability of universal machines to simulate one another, a string’s Kolmogorov complexity is machine-independent up to a machine-dependent additive constant, and similarly is equal to within an additive constant to the string’s algorithmic entropy HU(x), the negative log of the probability that U would output exactly x and halt if its program were supplied by coin tossing. Bit strings whose minimal programs are no smaller than the string itself are called incompressible, or algorithmically random, because they lack internal structure or correlations that would allow them to be specified more concisely than by a verbatim listing. Minimal programs themselves are incompressible to within O(1), since otherwise their minimality would be undercut by a still shorter program. By contrast to minimal programs, any program p that is significantly compressible is intrinsically implausible as an explanation for its output, because it contains internal redundancy that could be removed by deriving it from the more economical hypothesis p*. In terms of Occam’s razor, a program that is compressible by s bits deprecated as an explanation of its output because it suffers from s bits worth of ad-hoc assumptions.
Though closely related[1] to statistical entropy, Kolmogorov complexity itself is not a good measure of organized complexity because it assigns high complexity to typical random strings generated by coin tossing, which intuitively are trivial and unorganized. Accordingly many authors have considered modified versions of Kolmogorov complexity—also measured in entropic units like bits—hoping thereby to quantify the nontrivial part of a string’s information content, as opposed to its mere randomness. A recent example is Scott Aaronson’s notion of complextropy, defined roughly as the number of bits in the smallest program for a universal computer to efficiently generate a probability distribution relative to which x cannot efficiently be recognized as atypical.
However, I believe that entropic measures of complexity are generally unsatisfactory for formalizing the kind of complexity found in intuitively complex objects found in nature or gradually produced from simple initial conditions by simple dynamical processes, and that a better approach is to characterize an object’s complexity by the amount of number-crunching (i.e. computation time, measured in machine cycles, or more generally other dynamic computational resources such as time, memory, and parallelism) required to produce the object from a near-minimal-sized description.
This approach, which I have called logical depth, is motivated by a common feature of intuitively organized objects found in nature: the internal evidence they contain of a nontrivial causal history. If one accepts that an object’s minimal program represents its most plausible explanation, then the minimal program’s run time represents the number of steps in its most plausible history. To make depth stable with respect to small variations in x or U, it is necessary also to consider programs other than the minimal one, appropriately weighted according to their compressibility, resulting in the following two-parameter definition.
- An object x is called d-deep with s bits significance iff every program for U to compute x in time <d is compressible by at least s bits. This formalizes the idea that every hypothesis for x to have originated more quickly than in time d contains s bits worth of ad-hoc assumptions.
Dynamic and static resources, in the form of the parameters d and s, play complementary roles in this definition: d as the quantifier and s as the certifier of the object’s nontriviality. Invoking the two parameters in this way not only stabilizes depth with respect to small variations of x and U, but also makes it possible to prove that depth obeys a slow growth law, without which any mathematically definition of organized complexity would seem problematic.
- A fast deterministic process cannot convert shallow objects to deep ones, and a fast stochastic process can only do so with low probability. (For details see Bennett88.)
Logical depth addresses many infelicities and problems associated with entropic measures of complexity.
- It does not impose an arbitrary rate of exchange between the independent variables of strength of evidence and degree of nontriviality of what the evidence points to, nor an arbitrary maximum complexity that an object can have, relative to its size. Just as a microscopic fossil can validate an arbitrarily long evolutionary process, so a small fragment of a large system, one that has evolved over a long time to a deep state, can contain evidence of entire depth of the large system, which may be more than exponential in the size of the fragment.
- It helps explain the increase of complexity at early times and its decrease at late times by providing different mechanisms for these processes. In figure 2, for example, depth increases steadily at first because it reflects the duration of the system’s actual history so far. At late times, when the cellular automaton has run for a generic time comparable to its Poincare recurrence time, the state becomes shallow again, not because the actual history was uneventful, but because evidence of that history has become degraded to the point of statistical insignificance, allowing the final state to be generated quickly from a near-incompressible program that short-circuits the system’s actual history.
- It helps explain while some systems, despite being far from thermal equilibrium, never self-organize. For example in figure 1, the gaseous sun, unlike the solid earth, appears to lack means of remembering many details about its distant past. Thus while it contains evidence of its age (e.g. in its hydrogen/helium ratio) almost all evidence of particular details of its past, e.g. the locations of sunspots, are probably obliterated fairly quickly by the sun’s hot, turbulent dynamics. On the other hand, systems with less disruptive dynamics, like our earth, could continue increasing in depth for as long as their nonequilibrium boundary conditions persisted, up to an exponential maximum imposed by Poincare recurrence.
- Finally, depth is robust with respect to transformations that greatly alter an object’s size and Kolmogorov complexity, and many other entropic quantities, provided the transformation leaves intact significant evidence of a nontrivial history. Even a small sample of the biosphere, such as a single DNA molecule, contains such evidence. Mathematically speaking, the depth of a string x is not much altered by replicating it (like the bacteria in the flask), padding it with zeros or random digits, or passing it though a noisy channel (although the latter treatment decreases the significance parameter s). If the whole history of the earth were derandomized, by substituting deterministic pseudorandom choices for all its stochastic accidents, the complex objects in this substitute world would have very little Kolmogorov complexity, yet their depth would be about the same as if they had resulted from a stochastic evolution.
The remaining infelicities of logical depth as a complexity measure are those afflicting computational complexity and algorithmic entropy theories generally.
- Lack of tight lower bounds: because of open P=PSPACE question one cannot exhibit a system that provably generates depth more than polynomial in the space used.
- Semicomputability: deep objects can be proved deep (with exponential effort) but shallow ones can’t be proved shallow. The semicomputability of depth, like that of Kolmogorov complexity, is an unavoidable consequence of the unsolvability of the halting problem.
The following observations can be made partially mitigating these infelicities.
- Using the theory of cryptographically strong pseudorandom functions one can argue (if such functions exist) that deep objects can be produced efficiently, in time polynomial and space polylogarithmic in their depth, and indeed that they are produced efficiently by some physical processes.
- Semicomputability does not render a complexity measure entirely useless. Even though a particular string cannot be proved shallow, and requires an exponential amount of effort to prove it deep, the depth-producing properties of stochastic processes can be established, assuming the existence of cryptographically strong pseudorandom functions. This parallels the fact that while no particular string can be proved to be algorithmically random (incompressible), it can be proved that the statistically random process of coin tossing produces algorithmically random strings with high probability.
Granting that a logically deep object is one plausibly requiring a lot of computation to produce, one can consider various related notions:
- An object y is deep relative to x if all near-minimal sized programs for computing y from x are slow-running. Two shallow objects may be deep relative to one another, for example a random string and its XOR with a deep string.
- An object can be called cryptic if it is computationally difficult to obtain a near- minimal sized program for the object from the object itself, in other words if any near-minimal sized program for x is deep relative to x. One-way functions, if they exist, can be used to define cryptic objects; for example, in a computationally secure but information theoretically insecure cryptosystem, plaintexts should be cryptic relative to their ciphertexts.
- An object can be called ambitious if, when presented to a universal computer as input, it causes the computer to embark on a long but terminating computation. Such objects, though they determine a long computation, do not contain evidence of it actually having been done. Indeed they may be shallow and even algorithmically random.
- An object can be called wise if it is deep and a large and interesting family of other deep objects are shallow relative to it. Efficient oracles for hard problems, such as the characteristic function of an NP-complete set, or the characteristic set K of the halting problem, are examples of wise objects. Interestingly, Chaitin’s omega is an exponentially more compact oracle for the halting problem than K is, but it is so inefficient to use that it is shallow and indeed algorithmically random.
Further details about these notions can be found in Bennett88. K.W. Regan in Dick Lipton’s blog discusses the logical depth of Bill Gasarch’s recently discovered solutions to the 17-17 and 18×18 four-coloring problem
I close with some comments on the relation between organized complexity and thermal disequilibrium, which since the 19th century has been viewed as an important, perhaps essential, prerequisite for self-organization. Broadly speaking, locally interacting systems at thermal equilibrium obey the Gibbs phase rule, and its generalization in which the set of independent parameters is enlarged to include not only intensive variables like temperature, pressure and magnetic field, but also all parameters of the system’s Hamiltonian, such as local coupling constants. A consequence of the Gibbs phase rule is that for generic values of the independent parameters, i.e. at a generic point in the system’s phase diagram, only one phase is thermodynamically stable. This means that if a system’s independent parameters are set to generic values, and the system is allowed to come to equilibrium, its structure will be that of this unique stable Gibbs phase, with spatially uniform properties and typically short-range correlations. Thus for generic parameter values, when a system is allowed to relax to thermal equilibrium, it entirely forgets its initial condition and history and exists in a state whose structure can be adequately approximated by stochastically sampling the distribution of microstates characteristic of that stable Gibbs phase. Dissipative systems—those whose dynamics is not microscopically reversible or whose boundary conditions prevent them from ever attaining thermal equilibrium—are exempt from the Gibbs phase rule for reasons discussed in BG85, and so are capable, other conditions being favorable, of producing structures of unbounded depth and complexity in the long time limit. For further discussion and a comparison of logical depth with other proposed measures of organized complexity, see B90.
Assume that a Hilbert space is equipped with a qubit product basis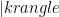 , and that a quantum state
, and that a quantum state 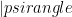 is specified as a set of
is specified as a set of 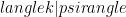 as usual. Then do I understand that the set of numbers
as usual. Then do I understand that the set of numbers 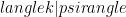 has logical depth? More broadly, is this essay building toward a point-of-view, in which an essential difference between classical and quantum state-spaces is that quantum states generically have nontrivial logical depth?
has logical depth? More broadly, is this essay building toward a point-of-view, in which an essential difference between classical and quantum state-spaces is that quantum states generically have nontrivial logical depth?
No, I am not building toward that viewpoint. This post was mainly about logical depth as a notion based on classical computational complexity and classical algorithmic information. The quantum version would be developed similarly, based on quantum versions of computational complexity (e.g. BQP) and of algorithmic information, so most quantum states would be shallow, like most classical bit strings.
The quantum case seems to raise some weird issues. For example, most n-qubit quantum states actually require Omega(exp(n)) two-qubit gates to create from a fixed state, or perhaps more appropriately, Omega(exp(n)) steps of a quantum Turing machine.
Markus Mueller, in his thesis used a definition of quantum Kolmogorov complexity which is the smallest quantum state that can be input to a universal quantum Turing machine to produce a target state. This addresses my concern, but hardly seems canonical. Approximation also seems like a trickier issue.
Here the idea is to conceive one broad logical-depth answer to three concrete questions: unpolarized qubits is initialized to
unpolarized qubits is initialized to  polarized qubits, and then (by a complex process) a quantum computation is performed?
polarized qubits, and then (by a complex process) a quantum computation is performed? random-state flip-flop gates is initialized to an array of
random-state flip-flop gates is initialized to an array of  zero-bit gates, and then (by a complex process) a classical computation is performed?
zero-bit gates, and then (by a complex process) a classical computation is performed?
• What is it that increases (besides overall entropy) when an ion-trap quantum register of
• What is it that increases (besides overall entropy) when an semiconductor memory register of
• What is it that increases (besides overall entropy) when glucose and sodium ions on opposite sides of a cell membrane are co-transported, and then (by a complex process) cell division is performed?
Because an encompassing answer involving “logical depth” is sought, we are reluctant to privilege quantum dynamical state-spaces over classical dynamical state-spaces … especially because (in practice) the boundary between these two classes of state-spaces is notably indistinct.